It should be noted in the doomed Air France 447 flight, the plane activated the stall warning because of a high angle of attack that was leading to stall. (thanks pdx for the corrected info)
At some point the system rejected the data and stopped the stall warning because the angle of attack was so severe that it considered the data erroneous. This is speculated to have caused the co-pilot to keep pulling back on the stick and to maintain the stall because everytime he let the nose of the plane come down the stall warning activated again as the AoA was decreasing into the range that the airplane considered a real signal. https://www.vanityfair.com/news/business/2014/10/air-france-...
A plane's instruments, the actions software takes, and it's interactions with the humans that fly the plane isn't as simple as an if statement.
If anything, fewer and simpler controls or automated systems are easier to debug and work around than a plane that has an internal calculus of what is valid data.
Air France 447 crashed because of a stall caused by a severe AoA that MCAS might have prevented (if MCAS simple pushes the nose down at high AoA it might. I am unsure of the exact implementation). MCAS obviously had a different impact on the Lion and Ethiopian Air Flights.
The challenge I think is to keep two things separated, one is the flight control laws that the system is implementing to keep the plane in the air (to the best of its ability), and the other is the situational awareness indicators for the pilots so that they can tell what what the plane is "thinking" about how it is flying (or not).
The closest analogy I can come up with is the SQL explain command. That command will generate the complete decision tree for how records are included or excluded from a SQL query. The air equivalent might be display that shows the flight status, and the state of the instruments that are being used to determine that status. And then it is up to the pilots (or DBA :-) to figure out if what is happening is what they think should be happening.
To use this particular example, it is, in my opinion, negligent on Boeing's part not to include an indicator for every change in the flight control laws. If MCAS activates to avoid a stall it should always indicate that it is, and why it is activated. It has been reported that this was an "extra price" option for the jet, and it is that choice that makes it feel negligent to me.
Generally, there seems to be enough indications with backups in the cockpit so that the pilot can ascertain what is going on with the aircraft reliably (backups and such), but what was missing here was, again in my opinion, was the rationale the plane was using for the flight laws it was implementing being available as well.
This is not the problem. MCAS in itself sadly is the problem.
They had to solve the issue that the pitch-up moment shouldn't be accelerating on its own just depending on AoA, which was (aerodynamically) inevitable without automated adjustments due to the placement of the engines.
They had to resort to the worst possible cludge, since they weren't even allowed to add new electrical systems (which would have caused a recertification and/or a retraining), so they resorted to an already existing system (assisted trimming by autopilot).
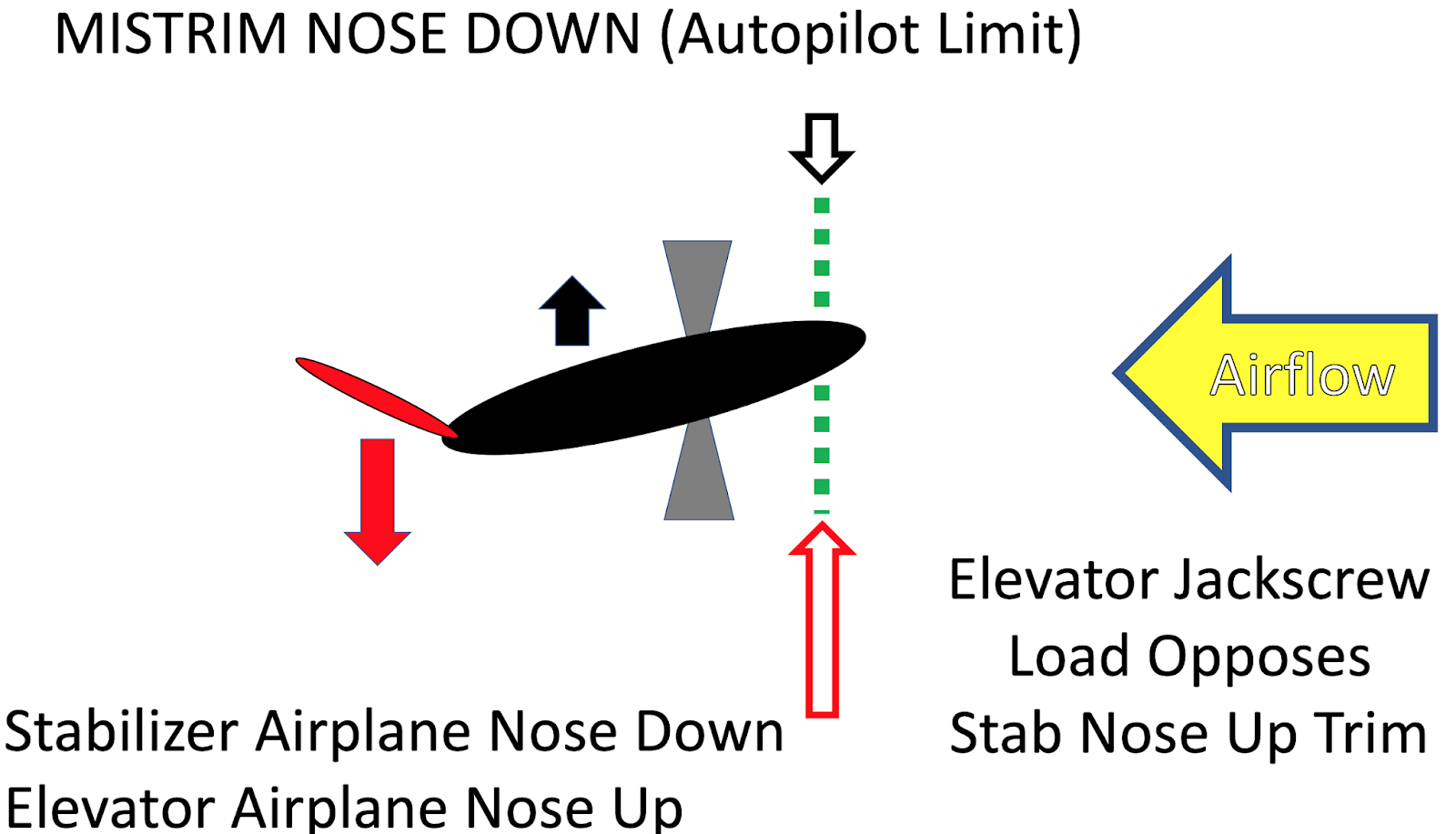
The effect of MCAS is only "fixed" by manually adjusting the trim, which involves moving a jackscrew which holds the last section of the elevator at a fixed angle. Unfortunately the required force of moving this jackscrew increases with the airspeed. There is no easy way out. A bit more background can be found here: https://www.satcom.guru/2018/11/stabilizer-trim.html
Btw, the extra price item was an AoA disagree warning. This is related to MCAS in a way like an odometer failure to traction control. It wouldn't have helped, if pilots stuck to their memory items and checklist (which they have to: they recognize runaway trim and have to react accordingly).
To get a slight feeling what it means to have runaway trim (without assistance which they had to disable in concert with MCAS) please have a look at this video:
https://vimeo.com/329558134
The problem with this approach is that it does not generalize. You might think that if pilots just had this one piece of information, it would be obvious what's wrong, so let's provide that information. But if you apply that consistently to every system, the crew will be buried in notifications all the time, most of which are perfectly normal, and most of the rest are normal responses to the abnormal conditions produced by the actual fault.
Even in a space shuttle, the flight crew did not see most of the data, and NASA had a room full of engineers following the telemetry.
When you have less than a minute to save everybody, the last thing you need is something like an SQL explain result.
> It has been reported that this was an "extra price" option for the jet, and it is that choice that makes it feel negligent to me.
not quite. the things they offered for extra were the AoA sensor readouts and an annunciator for AoA disagreement. the mcas was not part of that and the mcas was not briefed in the difference training from the other 737 models. the mcas taking input from a single sensor was to blame. it should not have activated when there was substantial disagreement from the two sensors. it also should have 3 sensors and vote on agreement and not just difference.
That's what I wonder since I heard of the two sensor thing. Why wheren't there 3 sensors or even more. We omit those kinds of failures for the simplest blog style websites. Feed that info into 3 flight controllers for that matter and fall back to Manual flight in case less than two agree.
It wasn't due to the cost. It is the whole business of avoid pilot retraining - which is apparently "must-have" for airlines. At some point, Boeing prioritised papering over the fundamental difference in the flight characteristics of MAX _above_ the pilots' needs to be informed of what is actually happening with the plane.
His proposal makes no sense. Under his new logic, it would be fine for the MCAS to continue forcing the trim to full deflection and crash the plane if the AoA was stuck anywhere between 15 and 24 degrees.
He's simply not solved the root problem and added a bad kludge for a single error case (AoA stuck > 25 degrees). While at the same time removed a potential safety control for a real world case where the AoA was validly over 25 degrees.
Note: I am assuming by RUNAWAY_TRIM() he means LET_MCAS_ADJUST_TRIM = TRUE; since runaway trim means something entirely different to my mind (that the electric trim is stuck/faulty and causing the trim to run to full deflection in one or other direction).
It is difficult to be sure from the flight data chart that was published in the Seattle Times, but it looks possible that the faulty AofA reading was below 25 degrees for most of the Lion Air flight.
Reading between the lines, Greenspun has presented these crashes as "the first mass killings by software". That claim looks clearer if you present it as wholly due to the absence of a few common-sense lines of code, and downplay the other systems design issues, such as the lack of triple redundancy, the failure to use the dual redundancy to detect sensor error, and the fact that the system was unnecessarily powerful, being able to drive the trim all the way forward.
From my pilot perspective, if a fellow pilot took the action MCAS did, I would consider it homicidal. This is based on the last instance of MCAS activation at ~05:43:21, airspeed is already exceeded maximum operating speed (Vmo), MCAS commands 1.3 units of nose down trim inside of 5 seconds, which changed the attitude to ~18 degrees nose down within 6 seconds. The vertical acceleration momentarily went negative, meaning everyone in the plane came off their seat, and anyone or anything not strapped down went to the ceiling. Soon after this we can see their maximum yoke nose up inputs up to that point, clearly this is the struggle point, and it was not effective, the mistrim was too great.
At the altitude and airspeed at the time this last nose down was commanded, it can lead to only death, it's not recoverable, so yeah mass killing by software is not an extreme claim.
If you view the MCAS as a control system that is a safety component of the 737 MAX, then you need a really good reason to completely cut off that safety system when a particular sensor input goes above a given threshold. In this case the argument being made is that if the input is above 24 degrees the safety system should be turned off, potentially leading to a stall. It's almost an argument against having that system entirely.
The problem is much more complicated than this and requires thinking end to end about 1) what the purpose of the system is, 2) when and how it should operating, 3) how much control it should have, 4) how it's activity is made visible to the pilot when it performs any control, 5) how and under what conditions it should automatically disable itself, or 6) be able to be manually disabled, and 7) how the pilot is made aware of all of these situations in a way that doesn't cause confusion in potentially complex scenarios involving other failures and alarms going off, and 8) proper training so the pilot can manage the plane when the characteristics have changed after the system is disabled. Oh, and 9) in this case since it's impossible for a pilot to manually trim a 737 when it's above a couple of hundred knots, making sure an electronic trim assistance function is available in this scenario (which it wasn't due to tragic idea to overload the use of the trim runaway cutout switches).
And I am probably missing a bunch of things, which is part of the point.
To be clear, I do not object to the 'verdict', but I do not think it helps to suggest that all the issues raised by these crashes can be dealt with just by giving each sensor one or two somewhat arbitrary thresholds beyond which they should be ignored. While I cannot think of any reason not to have adopted the proposed solution within MCAS, and it would have prevented the Ethiopian Airlines crash, it would not have eliminated the possibility in other circumstances (possibly including Lion Air), on account of the other problems with MCAS. If, in these cases, the sensors had failed to a plausible value (say, 15 degrees), the outcome would have been the same.
A commonality in AF 447 and the two MAX cases: angle of attack is not displayed to the pilots.
A substantial difference between them, is automation had totally checked out in the 447 case, whereas in the MAX cases automation took action contrary to reality.
I let the engineers argue over redundancy. As a pilot I think it's a factor, but far less so than the pilots being denied knowing their airplane.
447 pilots had not undertaken any in-flight training, at high altitude, for the “vol avec IAS douteuse” procedure or on manual aeroplane handling; while the MAX pilots had no training expressly on MCAS upset so they could experience the exact consequences of ensuing mistrim, the difficulty of solving that mistrim at low altitude, and the aggressiveness of MCAS in any subsequent nose down. MAX pilots are additionally denied knowing about the true pitch up tendency in high angles of attack without the benefit of MCAS (either it wrongly thinks AOA is OK, or stab trim is cutout).
The Ethiopian Airlines pilots had the situation progressing toward stability. They had (apparently) re-enabled electric trim to give them enough authority to reset the trim, and had a sane attitude. But then within seconds they lost their chance as MCAS took incredibly aggressive action that put them in an unrecoverable 40 degree nose down attitude.
There really is no substitute for training. I don't accept that the "fix" for the MAX is a software update alone. Simulators must be capable of showing various kinds of MCAS working, not working, and perturbed (erroneous sensor input) cases, at various phases of flight. All the excuses to avoid training are bullshit.
Yes it was 1.3 units of change inside of 5 seconds, without respect to being just over Vmo (maximum operating speed). If a human pilot did that in the same situation, it would be considered incompetency or sabotage.
Shown on the same page at the same time, vertical acceleration went very slightly negative as a direct result of this MCAS nose down change. Everyone came off their seat, including the pilots, and at that same time you see yoke position changes downward (less nose up to be exact) which made matters worse even though they were already doomed at that point.
The real question is: what training would you drop in order that the pilots get this alternate training? You can't just say, "train train train"; eventually the pilots have to actually fly.
- You've produced no evidence these pilots are at any training limit, you just made that up, so I call bullshit.
- I'm a pilot and a former flight instructor so I have some credibility in refusing a binary choice like you've proposed. It's not that much training. I had to do difference training for checkouts on a regular basis (giving it and receiving it) and it's not high quantity training, it is high quality training.
- The strongest argument there's plenty of opportunity for training is the fact the MAX had the same type certification as the previous NG model series. So what's the worst case scenario for difference training? It'd require an aircraft type certificate, which will require pilots undergo training and checkout for an additional type rating.
Quite a lot of pilots have multiple type ratings, it's not unusual, in fact the pilot of Ethiopian Airlines 302 had type ratings for B737-7/800, B757/767, B777, and B787. What, was he only training and never flying?
This is incorrect. If you read the original script of pilot conversation in the cockpit, you'd know that he simply forgot he was pulling back on the stick. He disregarded clear pilot training and did what he was exactly not supposed to do, I reckon out of nervousness. That flight, needed a better pilot. Period.
Forgot? Better? Neither of those things is supported by the final report, the cockpit voice or flight data recorders.
The occurrence of the failure in the context of flight in cruise completely surprised the pilots of flight AF 447.
Which pilot needed to be better?
The crew, progressively becoming de-structured, likely never understood that it was faced with a “simple” loss of three sources of airspeed information.
and
de-structuring of crew cooperation fed on each other until the total loss of cognitive control of the situation
OK so you need two better pilots, right? And what specifically would make them better in your view?
The final report is pretty clear, the most relevant cause bullets are on page 203, there's no need to speculate and provide your own version. It very clearly cites training deficiencies, cockpit ergonomics in that there was no clear display of airspeed inconsistencies and flight director indications that could have led the crew to believe their actions were correct even though they weren't, and significant simulator deficiencies.
The training and ergonomics basically set them up to be shocked at the situation they were in upon autopilot disconnect.
BEA even blame regulatory oversight of Air France for an inspection regime that failed to identify any of the rather numerous problems BEA found across the board.
Pinning this accident on a pilot is inappropriate.
You can say what you like, but that was incompetence and no technology can make up for downright incompetence.
The report statements are diplomatic. No report will point fi ger at anyone. In that particular case, the entire conversation in the cockpit was publicised. So, instead of letting others tell you what is and what is not, learn to read and draw opinions for yourself. Just because the investigators didn't explicitly say it, doesn't mean I'm wrong.
The pilot who have been pulling on the stick for a very long time was the incompetent pilot there. The guy who did the exact opposite of what should have been done during a stall warning out of nerves. That's incompetence. Many factors might have caused that unfavourable scenario, but he brought that plane down.
Fascinating. But it seems like the kind of scenario that would be odd for the pilot, no? You nose down, a stall warning goes off, so you nose back up again? That's exactly the opposite of what a pilot would be trained to do, right?
I'd imagine in a car, if my vehicle warned me that I was going too fast when I slowed down, my reaction wouldn't be to speed the vehicle back up to avoid the warning...
It's not well sourced. It's a speculation in an old Popular Mechanics article published before the official accident report. The official accident report does not identify the sidesticks as a factor in the crash (because they weren't).
Downvotes are so cool, right? Just post your better informed opinion and enjoy the upvotes. This has the side-effect of not just informing me but others about your more correct opinion.
The thread you link to explains why the sidesticks are a red herring:
>Again, the stick inputs from the PF are very easy to see if you just look at them.
You would see that immediately if you sat in an airbus pilot seat.
The PNF is going to spend most of his time looking at the instruments. He's hardly any more likely to be looking off to the side at his own control stick than he is to be looking at the other control stick, so linking them would be unlikely to make any difference.
I didn't say anything about sidesticks (in a comment below i did). I don't believe myself that the sidesticks were a real factor in themselves - but if the PM had sensed that PF (bonin) was pulling up he would have reacted earlier.
The PNF wouldn't have sensed anything because his hand wouldn't have been on the stick.
The premise of the Popular Mechanics article is that for a significant period, each of the pilots thought that they were the PF and were unaware that the other pilot was making stick inputs at the same time. This is unlikely, because the Airbus has a clear "dual input" warning. If you read the transcript, you can see that there's actually quite a lot of discussion between the pilots about who is in control. It was only the captain who had any clear idea of the correct control inputs to make, and he wasn't seated at the controls at all, so linked sticks wouldn't have made any difference to him.
Yes, if memory serves in AirFrance 447 that upon finding out the co-pilot had been pulling up the whole time the other pilot is shocked to hear this and realizes the problem. I remember being really affected by this so I went out and found the transcript:
02:13:40 (Bonin) But I've had the stick back the whole time!
[At last, Bonin tells the others the crucial fact whose import he has so grievously failed to understand himself.]
02:13:42 (Captain) No, no, no… Don’t climb… no, no.
02:13:43 (Robert) Descend, then… Give me the controls… Give me the controls!
What you're pasting there is an editorialized quotation of the transcript from an old Popular Mechanics article. The transcript and its English translation are here:
> my reaction wouldn't be to speed the vehicle back up to avoid the warning...
In car you can see and feel what's going on. In a jet at night, with complex behaviour in 3D, you'll have much less sensory input, close to zero. Hence Instrument flying.
The final report says it's impossible to evaluate the level of fatigue as they have no data on their sleep during the stopover. But from the CVR, the report says the crew showed no signs of objective fatigue
> everytime he let the nose of the plane come down the stick shaker activated again as the AoA was decreasing into the range that the airplane considered a real signal
That's true, but the pilot response was insanity. When the stick shaker comes on you push the nose down every time without question, unless perhaps you're at very low altitude and then you might be in an unrecoverable situation anyway... but you don't pull back :)
AF447 was an Airbus 330 which does not have a physical stick shaker. It has a "Stall Stall Stall" warning that sounds and was likely drowned out by the other alarms that were filling the cockpit.
A330s also have disconnected sticks, so when a pilot has input on one side of the plane, that input is not replicated on the other side of the plane.
>AF447 was an Airbus 330 which does not have a physical stick shaker. It has a "Stall Stall Stall" warning that sounds and was likely drowned out by the other alarms that were filling the cockpit.
Just to be clear, an Airbus 330 won't let the pilot maintain an attitude that could lead to a stall, so it has a much higher degree of protection than a simple stick shaker. The situations in which these protections are turned off are situations in which a stick shaker would also fail to function reliably.
I suggest to read a bit more about AF447. This was 90% the missing idea of the other pilots that one pilot (i.e. the pilot flying) could be so extremely uneducated(i.e. stupid) to try to pitch up while stalling is imminent/occuring. The remaining 10% is the airbus fuckup of mixing inputs of both sticks.
1. The pitot tubes froze (this was already a known possibility) and this particular plane was scheduled to replace those tubes;
2. When the speed metrics became unreliable, system didn't do anything uncommanded, disengaged autopilot gracefully, notified the pilots and handed control over to them;
3. Stall warnings went off and one of the pilots continued to pull on the stick (this baffled other pilots I heard speak about this too because this is the exact opposite thing to do during a stall)
4. It's clear from their exchanges in the cockpit that this particular pilot was very nervous during the whole thing.
What's complicated about that? I can't see how a computerised system could have helped here. Computer had no reliable grounds to make a decision and it did exactly what it should and what should have neen expected by the pilots at the time.
The other problem with AF447 was that the pilot and copilot were giving conflicting instructions to the plane and there wasn't any feedback that they were doing so, and that the senior pilot was taking a nap...
Interesting. So the system under consideration consists of both the airplane and the two pilots. Is this part of the design effort — I guess it is — and how do we even model the combination of technology and humans?
It's interesting to me that the system would be designed to detect that a sensor is feeding it bad data, then go back to trusting that input after it had been determined to be bad.
With all due respect, this sounds too much like the kind of armchair quarterbacking that routinely appears on HN when avionics/politics/astronomy is mentioned, where a lone programmer feels competent enough to criticize an industry for missing "something obvious".
I mean, this particular change might have saved the particular 737, but I'd rather hear it from someone who actually knows how 737s fly.
I too have hundreds of flights and am also a programmer, but I would not assume having both skills would make you anything more then an armchair quarterback. If you have not written code that runs planes, what knowledge are you basing your idea off of. IMO.
i too also play games, but i wouldn't assume to tell a game developer how to write their code.
I agree - being a pilot and a programmer is neither a necessary nor sufficient condition for being able to diagnose and solve an issue in a system as complex as a modern airliner. In fact I don't think any individual is capable of doing so on their own; maybe the sole exception being someone like the engineering lead of avionics for the 737 Max, who is probably not a pilot, and probably only a programmer in so far as it was a component of their engineering education.
Honest question, is his experience in small aircraft applicable at all to jetliners? How much carryover, beyond core theory of flight dynamics, is there from piloting a single prop to an Airbus or even a regional jet?
The thermometer sensor and circuitry might be perfectly ok, still the 452 number might be a single digit gone bonkers in the panel, so that data being transmitted (maybe also recorded?) is ok while the readout is plain wrong. A human acting according data being shown there might react very differently from someone reading the temperatures log. Sometimes software problems can be awfully subtle.
Digital thermometers usually have triple digits to be able to display numbers in the low 100's. I could see one of them failing in a weird way and displaying 452.
I was as confused as the other commentators by this post until I realized that fixermark is thinking of analog thermometers with a physical dial, while we (and probably the author as well) are envisioning electronic thermometers with digital displays.
Philip Greenspun is, in fact a programmer. He's probably best known in these circles for the quote "Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp."
It is possible to be both a pilot and a programmer.
I agree that we frequently see this on HN in regards to aviation. However, I don;t think it applies to Greenspun. He's a knowledgeable and active pilot himself.
Lots of people are, that doesn't mean they aren't armchair quarterbacking. I know how to fly airplanes and helicopters, does that make me an expert on the flight dynamics of 737 MAX?
That still doesn't mean he knows anything about writing code for flight control systems in commercial environments. Maybe he's written some toy code in MATLAB demonstrating some things, that's never undergone testing on a real airframe.
Are there any airliners for which a sustained 60-70 degree angle of attack over a span of several minutes is not overwhelmingly likely due to sensor failure?
Even there though, the fact that the Pats scout team ran that exact play twice in practice with the backup nickelback in was something that the coach perhaps could not have anticipated?
Any result other than an INT means Lynch still has a chance to run.
This type of elitism has no real place in hopefully constructive conversation.
I'm not going to ignore a well thought out point because someone doesn't have a PhD in the exact question under rumination.
And "armchair quarterbacking" tends to translate to "Request For Comment" in my book. I.e. a coming together of disparate ideas and areas of expertise to more fully render the extent of a problem.
This seems equivalent to "it is just a button, how hard can it be?" People outside of software rarely see the complexity they are suggesting or asking for.
Philip Greenspun is, in fact a pilot. He is not a 737 pilot, but probably has a better idea of how a 737 works than the average HN armchair quarterback.
Do we actually have the raw data from the sensor in the flight recorder, or do we have the flight computer's account of that sensor's data?
> IF AOA > 15 AND AOA < 25 THEN RUNAWAY_TRIM();
And if the AOA is frozen at 16 due to some fault? What is a loss of signal interpreted as? Does it use last-known value? 0? 100?
How often does the AOA get sampled? Is there any attempt to smooth the data? Was the data corrupted (bit errors) during transmission/reception? Perhaps there's a flaw in the hardware (or microcode) protocol implementation of the data bus (or whatever it would be in this case) doesn't disregard packets with parity errors? Or perhaps it only checks for 1 bit of parity and it needs to check for 3? Or perhaps it's sending int64 and the flight computer is expecting int32.
It's all so simple to make completely uneducated guesses.
When Boeing made such obvious mistakes such as "don't re-command full-nose down after reset" that should have been caught be any competent user acceptance / QA testing, I have to call the entire engineering effort into question. I cannot assume they did even 1 thing correct in this system, and it really needs to have an independent review of the entire system hardware and software implementation.
Philip Greenspun's speculation is a plausible concern, that is all it needs to be a valuable point, that type of data limit handling ought to be considered as the system is looked at. I read his post that he was talking a specific simple example, all the other types of things you mention could also be looked at. How the AoA sensors failed, any potential issues with signal handling, and especially what happened with the Lion Air AoA sensor repaired in Florida need to be investigated, that sensor repair sure seems to be. (BTW data handling in aviation is pretty interesting,
Greenspun is a fairly unique combination of EE/CS/past MIT lecturer/geek and experienced pilot, including holding an ATP certificate and flying for regional airlines.
The system as implemented could not have a "re-command full-nose down after reset". To start with there is not really a "reset" for MCAS. The pilot's only way to fully disabling MCAS continuing to do bad things is via STAB TRIM cutout switches. The STAB TRIM cutout switches are required to handle lots of other problems. e.g. runaway full nose down trim. The stabilizer trim system itself is a dumb as a rock, and has no idea where the trim should be set to if the power is restored to it. I suspect the only likely sensible behavior of the trim system itself is that it makes no automatic change. If MCAS is driving the trim wrong and if it was possible to remove the MCAS input to the trim system then the pilot should be able to reset the trim they want (with then hopefully functioning electric trim switches), or allow the autopilot to do it (outside of MCAS the A/P is the other automatic system that manages the stabilizer trim). The problem is that was not anywhere in Boeing's plans here, there was no way to separate MCAS going nuts and commanding extreme trim changes, from the actual stabilizer trim system.
However I do agree with your sentiment about (all the other) bad mistakes. In my view when a seemingly largely self-regulated group goes off and designs something with so many glaring issues (single AoA sensor source, lack of documentation and training, not even having a standard AoA disagree alert, etc.) and other possible issues (rationale of extension of MCAS trim authority, trim wheel forces needed to crank mechanical trim at stabilizer trim limits, Boeing slowness in responding to issues etc.) then everything needs to be looked at. My hope is there are very thorough investigations, of the actual systems, of all the proposed remedies (which separately, I am not convinced are enough), of Boeing, and of the failure of FAA oversight here. And I hope that is done as fast as possible, and as slow as really needed.
> all of the problems could potentially have been avoided by changing [code-snippet]
IMO, this implies the problem was a simple, single software problem. Firstly, that's in inaccurate assumption. Secondly, even if that assumption wasn't implied, one can't just say 'ooh, modify this if statement' with any authority because one does't know what the underlying algorithm looks like in the first place.
> The system as implemented could not have a "re-command full-nose down after reset".
For brevity, my comment lacked certain detail. The MCAS system was reset after pilots used the trim switches on the column. However, the MCAS did not account for this, and it's overall authority was allowed to point the plane full nose-down. See [1].
> In my view when a seemingly largely self-regulated group goes off and designs something with so many glaring issues
This is the point I'm mostly trying to make. When I read a column or comment that says "Oh, it was just the sensors" or "Oh, it was just the simple software problem," that's really helping Boeing's narrative. It's not just a simple mistake, it's a total failure of Boeing and regulators and cannot be understated.
Sorry to nitpick on one thing here; but I don't know that having an AoA disagree alert would be that useful. There was already an airspeed disagree alert, and AoA disagree strongly implies airspeed disagree, because AoA is involved in the airspeed calculation. Furthermore, knowing an AoA sensor is broken wouldn't be super useful without a workable procedure to do something about it; in the Ethiopia crash, the procedure followed was insufficient to regain control.
AoA disagree does not imply airspeed disagree. Indicated airspeed is purely a pitot and static pressure driven measurement. AoA is there largely as part of the anti-stall warning system, e.g. driving the stick shaker/pusher. An important point of having AoA sensors is to provide a stall warning systems that is independent of IAS, you don't want these systems crossed with each other.
B737 airspeed disagree I believe just requires 5 knots disagreement for more than 5 seconds between left/right IAS. No AoA involved.
There may be some confusion happening due to the events in the Lion Air B737 Max. The maintenance crew tried to address what they believed were ADIRU/ADR issues in previous flights... including as a possible source of erratic airspeed indications and airspeed disagree warnings. So there are some discussions of airspeed disagree in relation to that aircraft. There may be a lot going on there we don't know about yet, with say faulty ADIRU/ADR causing multiple problems. The ADIRU has inputs from the AoA vane but does not use that in calculating airspeed, it is using that to drive stick shakers/pushers and optional display AoA, and unfortunately in these cases to also drive MCAS.
Having a AoA disagree indication (and/or full AoA display option) might have allowed more prompt diagnosis of problems, but only if pilots were aware of and trained on MCAS. And even then, yes it's a minor point. I was not intending to claim that itself is a deep solution here, just not having a disagree warning as standard was a bad decision. The entire system, and overall approach taken by Boeing seems tragically deeply flawed.
I think the Ethiopian preliminary report says they were in IAS disagree for the whole flight too. I don't know what caused the IAS disagree. It played a role in the crash, since its checklist disallowed lowering flaps (which would have disabled MCAS) or throttling back (which would have avoided surpassing Vmo, which likely made manual retrim impossible).
Ah now my addled brain finally wakes up, well maybe. What may be happening here is the ADIRU is doing AoA based static port compensation. It will normally be a small correction, and I was trying to keep that out of the discussion because I thought there there have been reports of erratic airspeed in previous Lion Air flights and that was not jiving with small changes of airspeed I was expecting (and now I'm going to reread the Lion Air preliminary report to check what was reported). But to start with you only need 5 knots to trip the IAS disagree, so sure I'll expect it could trigger that (and also possibly an altitude disagree). But potentially more intersting is what does that usually small static compensation change do when the ADIRU thinks the AoA is really out of whack, does it keep applying the "correction" or does it ignore it? So that question circles back to be similar to what Greenspun is asking in the original article.
On the other hand, one of the contributing factors to the Three Mile Island nuclear disaster was the fact that the temperature sensors were showing their maximum programmed value of 280 degrees Centigrade. The actual core temperature was far far higher, but because the engineers designing the reactor never thought of the meltdown scenario, they programmed the temperature gauge to cut off at 280C, rejecting higher readings as obviously erroneous. This (along with a water gauge malfunction) led the reactor operators to misdiagnose the fault. The operators thought the reactor was overfull with coolant and was at risk of overpressure, when in reality the coolant was draining away.
I wouldn't be so quick to dismiss "obviously incorrect" sensor data.
While this is true, the point that it's worth thinking through the nature and consequences of "obviously erroneous" sensor data is still a valuable exercise holds.
If the temperature is past 280, generally speaking the same steps to diminish temperature can be taken (... I'm speaking broadly; this may not actually be true of nuclear reactors and if it's not, additional sensors with larger ranges were definitely warranted if there's discontinuity in the safety and disaster mitigation strategies at temps higher than 280).
There is no amount of automatic airplane wing trim that can arrest a 70-degree AOA. When the sensor's getting 70 degrees, the failsafe operation would have been to back out of the control calculation and defer to pilots.
I agree. In the case of the temperature sensor, my opinion is that the correct behavior should have been to show no reading, or an error value. At least that way the operators would have known that they didn't know the true temperature inside the reactor. As it stood, they saw high, but constant temperature, combined with rising pressure. That indicated that the water level was rising inside the reactor, so they opened drain valves to let water out. That was exactly the wrong thing to do, and it contributed directly to the severity of the meltdown.
Maybe 25 degrees is a little bit close to a real value. But think of this / flying along this line of text. That is what the AoA sensor was telling the FCC was happening to the aircraft. That's wildly out of range.
> Beyond 25 degrees, therefore, it is either sensor error or the plane is stalling/spinning and something more than a slow trim is going to be required.
I am not a pilot, and I'm going to take this pilot at his word. But my first question would be, if we add this additional rule into the system (that runaway trim turns off above 25° AOA), will any pilot ever need to know about this rule?
If the answer is "absolutely not, never" then that's all well and good. But if there's some way-out-there scenario where the plane is wavering between 24° and 26° AOA, and in that scenario the pilot needs to be aware that the computer's trim behavior is switching back and forth between two different laws, then I'd want to ask whether that's presenting pilots with too much complexity.
There's a rule of thumb in software design, when we're thinking about designing a complicated system to solve some messy problem. Will users have to deal with the system getting things wrong? If the answer is pretty much never, then the system can be very complicated if that means doing a good job. But if the answer is that the system won't always be right, and that users will have to step in some of the time, then making the system complicated inevitably means that users will have to learn all that complexity. I wonder if that applies here.
EDIT: Ah yeah, top comment right now is about Air France 447. That's a very good example.
There are several inexcusably egregious errors in the design of the MCAS system, and this "solution" addresses none of them.
- Single point of failure: The system makes command decisions based on the readings from a single sensor. The fact that nobody asked (or was bothered by the answer to) the question "what happens when that sensor fails?" is negligence.
- No re-training of pilots: Pilots were not aware of new ways in which the plane might take command away from them, and were left in the dark with only seconds to react to a deadly situation. The decision not to train was a cost and marketing motivated decision that sacrificed safety, to the tune of hundreds of lives lost.
Slapping on heuristics to condition unreliable data is not a good solution for life-critical systems. As another commentor pointed out, this is armchair quarterbacking, and it is not good armchair quarterbacking. This article should not be here.
The third factor to add to your list is that the design of MCAS makes the plane unrecoverable in some situations.
On the Ethiopia Air flight, it looks increasingly like the pilots knew what to do, but even after MCAS was disabled it was impossible to recover control because once trim was maxed out, adjusting the physical control trim wheels may have literally taken more brute strength than the pilots had, there was no way to reactivate electric trim control without also reactivating MCAS, and going nose-down to reduce load on the control surfaces to allow manual trim adjustment was infeasible because this all happened at 1000 ft. altitude.
>No re-training of pilots: Pilots were not aware of new ways in which the plane might take command away from them, and were left in the dark with only seconds to react to a deadly situation
Both the Lion Air and Ethiopian Air flights recovered from the initial MCAS. The mistake was assuming that pilots could reliably recover from a runaway trim situation. That might have been true when that was a more common failure and when pilots had more experience flying with manual trim.
Agree with you, though as a small correction it now appears (according to Ethiopian preliminary report) they made it to 7k altitude AGL, not 1k AGL. Still not so much to work with when you're above the plane's max airspeed and trimmed all the way down.
It's also misleading. The pilot pulling back on the stick makes the wheel harder to turn. If he stopped doing that and helped turn the trim wheel they would have been able to adjust it.
All that video really shows is that if you do it wrong it doesn't work. Not all that shocking
One thing I don't understand is that if the trim is stuck in a position that pushes the plane down, shouldn't the high speed (and therefore strong air flow) help to put the trim back in a neutral position rather than making it more difficult?
Now, imagine you have 5,000 such checks in millions of lines of flight control system code, many of them interdependent, and you have to fly the ship to test each one. You need to schedule time with the test pilots (who have lives of their own) and get the data dump from IT post-flight. It's aerospace so all this undergoes review, documentation, and signoff, and it all takes time. How do you prevent a single check from slipping through? It's not easy. These software engineers and others in the process screwed up, but it's a failure of processes and not just forgetting a conditional statement.
- The MCAS system has more trim authority than the usual (assisted) system
- It was originally intended to have an authority of +/- 0.6 degrees of trim
- Later it was discovered that this it not enough due to the aerodynamic effects of the engines becoming apparent also at lower speeds, which led boeing to increase authority to +/- 2.5 degrees per iteration with unlimited iterations until the maximum range
Unless I'm wrong disabling the MCAS system leaves the elevator at the current trim as set by the jack screw. That's really not the behavior you want. You want the control to return to neutral. Which probably isn't the way the trim mechanism is designed.
This whole thing smells like a bunch of dodgy decisions. Some of them recent and others historical. For instance not being able to manually adjust trim while the elevator is under load. That's dodgy, they got away with it because runaway trim is really rare.
Not a pilot yet myself, but I know exactly enough about flight physics and control to suspect that while you are likely correct about the MCAS jack-screw positioning being undesired, the solution is probably not to auto-return it to neutral.
If we assume MCAS is only disabled in an emergency, we don't want the result of cutting out an automated system to be further automatic manipulation of the control surfaces, right? That's one more weird behavior for the pilots to have to keep in their situational awareness while doing the most important step (i.e. flying the plane).
> we don't want the result of cutting out an automated system to be further automatic manipulation of the control surfaces, right?
You have two separate things a pilot may need to do. One is disabling the MCAS control action. In that case you do want it to return to normal trim. Second is disabling the Automatic/Electrical Trim. In that case you want it to stop and allow the pilot to set the trim manually.
Yes that's more or less it from what I gather. The trim cutout is designed to stop runaway from due to failure of the motor control circuit. Some ommon failure modes leaves the output stuck on. The only fix is to kill the power.
However if you kill the power to the trim motor and then turn it back on MCAS will blindly add more trim on top of the trim it previously added. It doesn't remember how much trim it's already applied.
> How do you prevent a single check from slipping through?
For a start, by not ramming an essentially new type through all test flying & certfication testing in 17 months before declaring it ready for service.
There is a reason that the Soviet Ministry of Aviation made newly-approved types fly only cargo and mail for a year or more; not just because their techniques were 'unsophisticated' per the Western view but also because they understood that introducing a complex system into a complex environment of weather and human factors couldn't be fully modelled but had to be subjected to prolonged real-World experience.
I'm sorry i'll have to mention that the software can be thoroughly tested in simulation flights. Funnily enough i was involved with some virtualisation software used to test booking systems for Airports. If you can virtualise a booking systems, trust me you can virtualise the on-board flights systems.
From what I have read it sounds like part of the problem is that manually adjusting the trim wheel requires more strength than at least some pilots possess due to the mechanical forces on the plane. I don't think it's reasonable to expect simulators to replicate those types of forces.
You can't perfectly simulate the pilot though, that's the big danger with human/automation hybrids.
As with what potentially happened to these crashes, the operating procedures might not be fully known by the pilot. The simulation might also allow the simulated pilot to do things that humans can't, for example turn the trim wheel when the jackscrew is under heavy load from the nose being pitched down.
No doubt you can test on-board flight systems, but you can't really compare virtualizing a booking system with flight systems, which are much more complicated and delicate. Now if you worked at SpaceX and worked on testing their flight systems, then I'd be more inclined to trust you.
I know what AoA is and yes, the calculation of AoA by itself is simple, but the corrective measure is not.
Classic 737s climb via trim, not constant stick inputs. This has changed slightly with the MAX but now you have automated AoA correction (involving trim). That's a nasty combination.
That's not nearly the case. MCAS is a stupidly simple system intended to cut in during very unusual phases of flight were a normal commercial flight would not be operating.
Sigh. I've reviewed almost everything written about the accidents including the information supplied by Boeing to the airlines to explain the function of the MCAS system.
There is no lower limit on the complexity of a system required to kill people.
> including the information supplied by Boeing to the airlines to explain the function of the MCAS system
So, you're essentially parroting Boeing's narrative IMO. Yes, they want you to think that the system is 'stupid simple' and it's 'no big deal, just one little fix' because obviously that's good for their business.
Maybe, the system required for safe operation is not so simple, and Boeing is no longer competent enough to create a system. Perhaps the 'stupid simple' system was all they were able to muster.
Or maybe they forgot to add the flying unicorns to power it.
I'm not sure why you think boeing would lie about it. Or how they'd convince the regulators in two different countries to cover it up since you can see the behaviour by reading the graphs in the preliminary report.
I accidentally copypasted my one time login code into the amount of bill payment and my ebank didn't refuse the sixty seven million dollar payment (I caught it before sending it). Needless to say, I don't have and never had even one percent of that money.
My brother one time actually succeeded in wiring ten million euros instead of ten million forints. The exchange ratio is 1:320. Obviously the account didn't have 10M EUR on it.
I just entered 300 USD as a courier tip into the food order app I just tried for the first time because I expected it'll just do 3.00 for me. I caught it before sending it.
All of these are lacking this kind of defensive validation. I recognize the irony of not even knowing the terminus technicus for it despite I am a senior sw developer with decades of experience.
I sell stuff on Amazon European marketplaces. I sometimes change the price; you have to do that on each marketplace (there are 5: UK FR DE ES IT) in the interface for sellers.
The decimal separator for UK/English is the dot; in all other marketplaces it's the comma. If you put a dot where a comma is expected it's silently ignored (so for example EUR 9.99 becomes EUR 999)... but "slowly": the dot you type appears normally, and then after some periodic ajax validation, it's removed.
I now know this and am careful about it, but the first few times I had my items priced at 100x their normal price, until customers emailed me to ask if this was normal.
It would maybe make sense to issue a warning if the new price differed from the old price by two orders of magnitude. But there's no warning.
I inherited a system that let you put AAA in the product price field and would persist it.
Validation is hard to get right so they simply didn’t try, not even common sense.
I’ve spent years thinking about the optimal way to structure validation and I’ve never come up with an approach I really like on an architectural level so I do the usual approach of simple sanity checks on the client and proper validation against business logic on the server but even that isn’t as isolated as I’d like.
To add another anecdote: The lead developer of bitcoin accidentally sent me a donation of 10 BTC instead of 10 USD (when it was about 300 USD/BTC). (I refunded it.)
When working on my PhD in mechanical engineering, I created fairly large data compilations and I would include some assertions like this. I'd make them assertions because I considered data that had these faults to be not worth adding, so if the data wasn't a typo then I'd just cut it.
It can be hard to think of good tests for data like this. Sometimes my assertions were wrong, e.g., I thought R^2 couldn't go below 0. That's actually false.
One I've found useful to spot typos was to check whether a column which is incrementing is in fact incrementing. E.g., if a table is ordered by the pressure tested at, then obviously there's a typo is the pressure is not increasing.
According to Captain Chesley Sullenberger (the former air force pilot who saved US 1549, dubbed the Miracle on the Hudson) that the existing avionics are not designed to take our best advantages[1]
Humans are much better suited for the doers role with
technologies monitoring us, instead of what we are
currently assigning the human component as exactly the
opposite.
If the leaked information so far is at all reliable, it seems that the MCAS system was obviously inappropriate for FAA certification; a single AOA sensor cannot be used as a critical component of a DIL B system, full stop.
The suggested change makes the system not actively crash the airplane under ordinary situations, but does not account for the increased load on a pilot due to the need to manually trim down under the conditions that a properly operating MCAS would be needed. If the MCAS is necessary to prevent crashes due to pilot overload, then this 10 character change is insufficient.
Sure the suggested change makes the cure no longer be worse than the disease, but doesn't address the fact that the cure was needed in the first place.
Another way of putting it is that the crash could have also been avoided by using this pseudo code instead of what is suggested:
IF FALSE THEN RUNAWAY_TRIM();
but the MCAS system wasn't added by Boeing because they wanted to spend more money on the aircraft, so it (like the fix suggested in the article) seems likely to be insufficient from the point of view of passenger safety.
If you read about Air France Flight 447, at some point instruments data went so ridiculously far from expected values that the stall warning stopped, because the computer did exactly what is suggested here: rejecting ridiculous data. So trying to fight the stall would... trigger the stall warning, adding confusion and cognitive load to an already dire situation (IIRC it is very likely, though we will never know, that the pilots didn't quite understand until the very end that the plane had stalled).
The "solution" described in the article seems to add more complexity and surprises to a system (MCAS) that already behaves in surprising and unexpected ways. Engineering is hard, adding a band aid on top of an ill devised clutch without carefully thinking, writing, and peer reviewing all the possible consequences, is unlikely to help.
This comment seems to say that Boeing has recently implemented a bunch of fixes to prevent MCAS from activating in various scenarios, which allegedly make MCAS safety a non-issue:
I'm not knowledgeable on planes, but some parts of this make me wonder if these fixes will cause the opposite problem.
For example if the two sensors disagree then MCAS now won't activate. How long until a crash happens because of that new behaviour? Either MCAS is necessary safety equipment, in which case this sounds dangerous, or it isn't, in which case why bother?
You are correct. The rather humorous aspect is that they really can't stick to the "no retraining" claim or really the claim the plane is airworthy because the plane is only certifiably airworthy when MCAS is operating.
So in short, yes. Their fix is introducing problems elsewhere. This characteristic is what has many thinking their was a series of grievous process, business, and regulatory errors layered on top of the known poor engineering decisions that came together to set the stage for these catastrophes.
> Either MCAS is necessary safety equipment, in which case this sounds dangerous, or it isn't, in which case why bother?
The situation is more subtle than that. A simple analogy is that MCAS is like ABS on a car. ABS is not required to drive a car safely and does not activate during normal driving. ABS activating when it should not can cause a crash. Likewise, the intended scenario in which MCAS activates is abnormal and requires a combination of conditions that are unlikely without several errors in judgement by the pilot.
There's another layer though: it's possible to get the 737 MAX into a situation where the standard stall recovery for other 737s, which starts with lowering the nose using the elevator is insufficient. Instead, both the trim and the elevator are required; MCAS does the trim part automatically.
The problem with this is the idea that this kind of software would ideally be written or specified with "if" statements.
I'm not sure about the argument that AOA values of more that 25° constitute an error, but a more plausible design would be a module that monitors the signal from the AOA sensor and classifies it into various advisory categories. That module could get complex internally but still have a clean interface, providing data of the form (AOA, Advice) where "Advice" would be an indication of the modules' conclusion or recommended action.
Rejecting ridiculous data is potentially a very subtle ML problem. To suggest that it should be taken care of in such a simplistic ad hoc way really doesn't do justice to the problem.
This needs more than an IF statement. This needs calculation of the rate of change of the variable, in addition to observing the value of the variable. Rate of change calculations are atleast an order of magnitude harder than just reading the variable. Doing it for infinite number of variables, in embedded, memory constrained, real-time systems is hard. So this wasn't going to be fixed via trivial 10 characters of code. But, yes, a more complex system would have avoided it.
The sensor reading could have just as easily been 24 degrees rather than 70 and caused the same crash w/ the author's proposal.
Not saying or excusing the failures that led to this crash, but it seems like an oversimplification of the needed solution to suggest that ridiculous data be thrown out, with the benefit of hindsight being used to determine where the threshold of "ridiculous" is.
Assuming that there are many software subsystems that need angle of attack input, it shouldn't be the responsibility of every one of those systems to try and determine if they are receiving bad input from the AOA indicator. Rather, there should be one angle of attack (AOA) sensing software system which feeds AOA data into all the other dependent systems. If the AOA sensing software system cannot determine a reliable value, then it should feed a value of "I don't know" to the downstream subsystems.
Then, all possible expertise about how to determine if the AOA input is valid (and I'm sure there are many, many, such factors, redundant physical sensors being just one) can be directed to that one AOA sensing system.
If MCAS gets an input of "I don't know" from the AOA sensing system, then clearly it is going to disable itself. So, a complex decision has been turned into a very simple one.
If you agree with me, then this is a really important example of why separation of concerns is so important.
> Despite all we've read about this subject, are we really still implying that this is a software problem?!
We don't know it's not a software problem (in addition to lack of hardware inputs). We don't know that anything in the system is fit for purpose whatsoever. That's what an obvious exclusion of basic failure testing tells us. That the system had NO critical oversight.
All the talk about how crappy Boeing engineering here was is bullshit and speculation and I am surprised PG participates in it. What we can discuss objectively here is incident response in which Boeing allowed the situation to continue after the first crash. How did they not run hundreds of hours of simulations, code reviews etc, etc on the system assumed to be at fault? How did they not immediately change the safety features associated with MCAS to be free and mandatory for everyone? Engineering mistakes happen and are hard to prevent. Business mistakes like this are a sign of terrible culture, lack of priorities and are an existential thread to the company.
It's not really speculation. The proof, as they say, is in the impact crater.
The only mystery left is, what is the nature of the paper trail that led to this catastrophe?
Was there malicious malfeasance? Overt and irresistible pressure to certify at all costs?
Was it all just a tragic mistake? We don't know. We only know the physical systems that contributed to the crashes, and some of the motivations that would have contributed. The technical implementation can be roughly inferred by any programmer, and it doesn't take a rocket scientist to figure out a ball was dropped somewhere for a plane development program to fall afoul of such a foreseeable failure state.
"The technical implementation can be roughly inferred by any programmer", "such a foreseeable failure state"... how many years of experience do you have?
How rude. Here I was thinking we were having a civil discourse over the Internet. More than born yesterday, less than since the Moon landing.
Regardless, my assessment is based on most juniors I've worked with. By their third year most seem to have already grasped the need to test for boundary conditions, and to ensure proper error handling for GIGO failure. Any 1 year+ with at least FizzBuzz levels of understanding can be handheld toward it with the right nudge, and in fact, the less experience they have the more eager and likely they tend to be to pick up on error handling since they haven't yet developed sufficient skills to be able to get their head around the "test you don't need to write" because the result can be inferred from a test at another level of the system (a frequent coping strategy that starts creeping it's way in with increased levels of familiarity with a complex system).
Any problem grokking the above points is usually solved with an impromptu exercise and lecture where I have the junior play the part of a computer until they realize just how much the computer "doesn't know", and has no capacity to derive from reasoning, unless it's actually coded/implemented to. I've not yet had a junior who failed to grasp this to some degree (though a recent one is giving me a run for my money), and become capable within a couple months of inferring two to three-function away error states to test for. Within the year, I can typically point them at an arbitrary code block and get back a reasonable testing surface.
Which brings me to my next observation, where I think you may be attempting to make a point:
If I run into juniors of 1-3 years experience who need coaching to fully understand what I explained above, then perhaps the average programmer is not capable of inferring what I claim.
To which all I can say is, my observation may be skewed, because I'm a bloody paranoid polyglot of a tester when it comes to safety critical systems. Even when I was pre-collegiate programming calculators, the more someone else actually depended on something, the greater the lengths I'd go through to test things before cutting them loose with anything I was producing for them. The THERAC-25 postmortem is bedtime reading for me, and I've pushed myself to understand computer science and software engineering as more than mere 'coding'.
If the argument then, is that I'm an atypical representative of my software composing brethren, then I'd like to know why in the $deity's name we're not triple-checking safety critical code at system integration time, seeing as we can assume this level of inattention to detail by the average programmer. Especially given as the languages these types of systems are implemented in are typically not the most 'friendly' languages.
This suggests cultural issues, undue pressure to fast-track approval, disincentive to raise red flags that could impede delivery, or an "over-the-wall" hyper siloing of expertise/responsibility that lead to the least experienced in complex system implementation being blindly trusted by those who had the experience to realize something was horribly wrong.
If the above doesn't assuage any concerns relating to my experience, I'm afraid not much else will.
You think I was rude asking you about your experience. Now think how rude this unsubstantiated allegation of obvious simplicity of the code in question is to the person who wrote it -- with the weight of hundreds of lost lives on their shoulders.
These control systems can get arbitrary complex. We don't know anything about the hardware this runs on and what it has to interface with. We don't know the constraints and age of the codebase. Nothing. To assume that this boils down to a simple if statement is something I would expect from a recent college graduate, or someone who has only worked at a web startup, not a person with 5+ years of real world experience building complex systems.
I agree about all the points about testing and business processes. We have enough evidence to conclude that unforgivable mistakes were made there (and I point to that in my original comment).
>You think I was rude asking you about your experience.
You asked for a number. Who I am, doesn't factor in. The experiences and insights I can bring to the conversation do. Of which I provided more than enough to get you in the right ballpark experiencewise.
>We don't know anything about the hardware this runs on and what it has to interface with.
These are essentially networked embedded microcomputers, likely utilizing various potential protocol stacks such as
CAN, CAN FD
AFDX® / ARINC 664
ARINC 429
ARINC 825
Ethernet
CANopen
for networking.
They are likely highly constrained, and must be compliant with DO-178B/C, which includes a need to verify the software down to the op codes spit out by the compiler.
The most popular languages for this purpose are known to be C, C++, FORTRAN, and Ada.
There's this wonderful place called the Internet where Engineers and other really dedicated people share information about what they use to do things.
>Arbitrary complexity
Is a possibility, but tends to be bounded by the fact humans still need to be able to implement and verify the systems they make in a reasonable amount of time. Which coincidentally, seems to have missed a few layers or so given we're here talking about this.
The world has very little that can't be found with a little digging, and in the interests of saving time, we tend to reuse technologies when appropriate from things like, cars, in other things, like airplanes.
If you can gain a mastery of how to network and program computers in general, you gain insights into how other physical systems, even though they aren't Turing machines, interconnect and propagate information and forces.
If you can then understand engineering principles well enough to decompose complex things into a network of simpler basic parts, and understand how to employ mathematics to analyze and predict the behavior of those systems, you can quickly formulate broad guesses about contributory factors to a failure state given the even small amounts of information.
And if you say all that's impossible to appear in one person, I don't know what to tell you. I'm not asking you to have faith, I'm asking you to think, question, imagine, and connect the dots between what information is available out there.
But hey, what do I know? I'm just a guy who objects to having credibility pidgeonholed based on some number instead of the content of what is being communicated.
I apologize if I sound aggravated or hostile, but I do not appreciate it when something as tightly regulated as aircraft out of the blue starts killing people, and the reason looks to be a lack of scrutiny/verification, rushed implementation, intentionally sparse communication, and unethical sales practices for whatever reason.
There are ways to do things, and there are ways not to do things. I expect a leader of an industry to at least show a level of effort such that I can entertain the benefit of a doubt that gross incompetence Or greed was not a factor. I have no such illusions left to me based upon what I've been able to work out. The cause is somewhere in their culture or business practices, and I want it ripped out into the light as an example to everyone, everywhere.
I don't care half as much about what happens to the people involved as long as it is enough to dissuade anyone thinking of doing the same thing from going down that path.
I have no practical experience with sensors but for those gained from a few university courses.
In one course, we were re-assembling systems on a weekly basis, and the touch-screens we used would all return somewhat quirky offsets, so I had to calibrate the input after each re-assembly because I could never be sure which module I was working with. I learned to never really trust a sensor.
And this was an undergraduate course. I would have assumed that in safety-critical applications, in a mature industry, performing every possible check on a sensor reading would be the obvious thing to do.
Was this particular case just out of the ordinary, or is it really that uncommon to do that?
There must be all kinds of neat things one could do with access to the raw sensor data. Perhaps manufacturers should be forced to make it available, so owners can hook up a laptop and run independent analysis software in real-time.
I imagine a frozen Angle Of Attack sensor would stand out like a sore thumb to a neural net that has access to all the sensors. In fact, I imagine it would return a suspiciously constant value even considered on its own.
This doesn't seem all that difficult, really. Teams at engineering universities do more challenging stuff for their master's project.
Completely off topic, but I hate Accuweather. The guy that runs it has lobbied left and right to keep the NWS and NOAA from being able to just deliver weather products because they'd cut into his revenue stream he's developed by charging people for access to public data.
Software CAN be far more safe then humans for tons of reasons. It's a matter of procedure and testing to ensure it's actually safe.
People are going to die, and that sucks. The hope is that we can use software to lower the death rate.
In this case: How did they have a system that can override the pilot without A) Clearly identifying why it's overriding the pilot and B) allowing the pilot to quickly disable it if they wish.
This could have been different, even ignoring how the MCAS didn't detect the strange readings.
* MCAS detects dangerous angles, beeps and has a clear light to alert the pilot to the situation
* Pilot understands there is no danger in stalling, disables MCAS
* They can now ground the flight or continue to their destination without the plan sending them to the floor.
Although based off what I've read about MCAS it only exists to fix a fundamental design flaw with how the 747 is certified, which is obviously an issue on it's own.
I'll be honest, I still prefer it to the world where lack of software kills people.
... I avoided running over that child I couldn't see in my rear-view because the infrared sensors picked him up as a mobile object intersecting my path and the backup warning screamed at me. I like not killing people, so I call that a win.
I am all for the sensors to give me information but when the systems take over control I am not a fan.
Cyclists in the EU have learned that the car sensors will slam on the brakes. Quite irritating when the car slams on the brakes and they are laughing at you.
The lane assist can be disabled and a cyclist who hard-brakes in front of me is taking their life in their hands because my Ford only stops if I touch the brake (it just stops as hard as it needs to to minimize risk of impact, regardless of how soft I push the pedal).
(Sidebar: I almost feel like that cyclist game is something that should be solved with more sensors. If it's a common issue, you really want a dash cam to capture their image and report them to police, as inentionally hard-braking to trigger a car safety system is clearly endangering their lives and the lives of the car occupants, since the auto-brake is designed with a bias towards injuring occupants over killing anyone).
I am an American too, renting an Audi in Germany has caused me many learning experiences. Like take the 30 minutes to learn the computer system before you take off because attempting to turn things off at speed is interesting when you cant find it.
Audi presense is nice, lane assist is nice, adaptive cruise control is nice etc etc but when its not nice it gives you whiplash or heart attacks
And that ever pervasive feeling that you know somwehere is a bug in that code which could yank your steering wheel sideways or slam on the brakes randomly
The cyclist issue is something I don't consider a fault of software or the car's design. Driving/Cycling/Walking in front of a high speed vehicle who has the right of way to the point that they need to break means you should not have been there to begin with.
The car's only other option is to hit the cyclist, so as far as I'm concerned it's doing it job correctly. Like you mention a dashcam is likely the only remedy here. Thankfully they're cheap and pretty common...
I think the grandparent is talking about a situation where the cyclist is _behind_ the car and not in front of it. A modern car that brakes hard can decelerate much faster than a bike, and therefore becomes a brick wall.
When I'm on a bicycle I try to avoid cars as much as possible (by being in a lane for bikes, or on the sidewalk) but sometimes we have to share the road. Then I'd rather ride opposite to traffic because at least I see the cars incoming and can avoid them.
When backing out the bikes can be 50 ft away coming fast and the car senses they will be close so it slams on the brakes way before anyone is in danger.
Whoops my bad! I thought you meant they were purposely traveling in front of the car, knowing it's sensors would force it to stop. It'd be super moronic and dangerous, but if you recognized the car model it would at least be possible.
This 'article' is very low quality and is written by a layman. If his main source of information is one line of wikipedia, he shouldn't be telling experienced engineers how to write flight software.
Furthermore, it is incredibly unsafe to reject so-called "ridiculous" data completely.
{kind=link}
At some point the system rejected the data and stopped the stall warning because the angle of attack was so severe that it considered the data erroneous. This is speculated to have caused the co-pilot to keep pulling back on the stick and to maintain the stall because everytime he let the nose of the plane come down the stall warning activated again as the AoA was decreasing into the range that the airplane considered a real signal. https://www.vanityfair.com/news/business/2014/10/air-france-...
A plane's instruments, the actions software takes, and it's interactions with the humans that fly the plane isn't as simple as an if statement.
If anything, fewer and simpler controls or automated systems are easier to debug and work around than a plane that has an internal calculus of what is valid data.
Air France 447 crashed because of a stall caused by a severe AoA that MCAS might have prevented (if MCAS simple pushes the nose down at high AoA it might. I am unsure of the exact implementation). MCAS obviously had a different impact on the Lion and Ethiopian Air Flights.
Basically, it's complicated.