I just tried this GGUF with llama.cpp in its UD Q4_K_XL version on my custom agentic oritened task consisiting of wiki exploration and automatic database building ( https://github.com/GistNoesis/Shoggoth.db/ )
I noted a nice improvement over QWen3.5 in its ability to discover new creatures in the open ended searching task, but I've not quantified it yet with numbers. It also seems faster, at around 140 token/s compared to 100 token/s , but that's maybe due to some different configuration options.
Some little difference with QWen3.5 : to avoid crashes due to lack of memory in multimodal I had to pass --no-mmproj-offload to disable the gpu offload to convert the images to tokens otherwise it would crash for high resolutions images. I also used quantized kv store by passing -ctk q8_0 -ctv q8_0 and with a ctx-size 150000 it only need 23099 MiB of device memory which means no partial RAM offloading when I use a RTX 4090.
I'm not sure how you can give the flamingo win to Qwen:
* It's sitting on the tire, not the seat.
* Is that weird white and black thing supposed to be a beak? If so, it's sticking out of the side of its face rather than the center.
* The wheel spokes are bizarre.
* One of the flamingo's legs doesn't extend to the pedal.
* If you look closely at the sunglasses, they're semi-transparent, and the flamingo only has one eye! Or the other eye is just on a different part of its face, which means the sunglasses aren't positioned correctly. Or the other eye isn't.
* (subjective) The sunglasses and bowtie are cute, but you didn't ask for them, so I'd actually dock points for that.
* (subjective) I guess flamingos have multiple tail feathers, but it looks kinda odd as drawn.
In contrast, Opus's flamingo isn't as detailed or fancy, but more or less all of it looks correct.
I wonder when pelican riding a bicycle will be useless as an evaluation task. The point was that it was something weird nobody had ever really thought about before, not in the benchmarks or even something a team would run internally. But now I'd bet internally this is one of the new Shirley Cards.
I use this metric now, and I suggest you change it per your imagination:
"Make a single-page HTML file using threejs from a CDN. Render a scene of a flying dinosaur orbiting a planet. There are clouds with thunder and lightning, and the background is a beautiful starscape with twinkling stars and a colorful nebula"
This allows me to evaluate several factors across models. It is novel and creative. I generally run it multiple times, though now that I have shared it here, I will come up with new scenes personally to evaluate.
I also consider how well it one shots, errors generated, response to errors being corrected, and velocity of iteration to improvement.
Generally speaking, Claude Sonnet has done the best, Qwen3.5 122B does second, and I have nice results from Qwen3.5 35B.
ChatGPT does not do well. It can complete the task without errors but the creativity is atrocious.
I mean look at the result where he asked about a unicycle - the model couldn't even keep the spokes inside the wheels - would be rudimentary if it "learned" what it means to draw a bicycle wheel and could transfer that to unicycle.
it's the frame that's surprisingly - and consistentnly - wrong. You'd think two triangles would be pretty easy to repro; once you get that the rest is easy. It's not like he's asking "draw a pelican on a four-bar linkage suspension mountainbike..."
Wouldn't this be more about being capable of mentally remembering how a bicycle looks versus how it works?
This reminds me of Pictionary. [0] Some people are good and some are really bad.
I am really bad a remembering how items look in my head and fail at drawing in Pictionary. My drawing skills are tied to being able to copy what I see.
I think it’s difficult to draw a bike exactly because you remember how it works rather than how it looks, so you worry about placing all the functional parts and get the overall composition wrong. Similar to drawing faces, without training, people will consistently dedicate too much area to the lower part of the face and draw some kind of neanderthal with no forehead.
is it possible to have greater success with the specificity? I don't think i ever drew a bike frame properly as a kid despite riding them and understanding the concept of spokes and wheels...
Interesting thought, I looked it up out of curiosity and fund 155w max (but realistically more like 80w sustained) for the mac under load, and just around 20watts for the brain, surprisingly almost constant whether “under load” or not.
the more I look at these images the more convinced I become that world models are the major missing piece and that these really are ultimately just stochastic sentence machines. Maybe Chomsky was right
No, they have "attention". There is unique logic going on in the deep layers of the neural network.
Even the standard introductory exercise artificial neural networks, handwritten digit recognition, already shows deeper understanding. These simple networks take in raw pixels and somewhere in the many layers recognize "curves" and "edges" and then "circles" and "boxes" and whatnot and eventually "digits".
I think there's a genuine debate about whether or not this is a form of intelligence. I think the oversimplified argument of them just being stochastic sentence machines mostly comes from people who don't understand how they work. But I also think there's a much more nuanced version of this argument offered by people like Chomsky that should be taken seriously
> No, they have "attention". There is unique logic going on in the deep layers of the neural network.
Any specifics? That doesn't say anything about them not being sentence generators. And it's pretty well known that the LLMs constantly spew out fantastically grammatically correct sentences that have no logic to them whatsoever.
> These simple networks take in raw pixels and somewhere in the many layers recognize "curves" and "edges" and then "circles" and "boxes" and whatnot and eventually "digits".
That sounds like a version of anthropomorphizing. It is my understanding that it is a completely open problem as to what neural networks are actually doing in their internal, deep layers.
> I think the oversimplified argument of them just being stochastic sentence machines mostly comes from people who don't understand how they work.
I mean, that's effectively a logical fallacy, so it's not a strong argument.
From that perspective, which is totally correct, it makes you wonder what other domains of knowledge look like when pushed to the boundaries of our capabilities as a species.
Do you know of any other statistical model that can "hallucinate". They clearly have emergent capabilities that come from scale that are absent in any other statistical model we've ever dreamt up.
We know that LLMs build complex internal representations of language, logic, and concepts rather than just shallow word-counting.
If you deny that then you probably have an elementary understanding of how they work. Not even Chomsky denies that. The real argument imo is whether those internal representations constitute an actual "understanding" of the world or just flatten out to something much less interesting.
The Chomsky argument feels like it's moving in a different direction than what's actually useful to know. Whether or not these models have "real" understanding, they're clearly capable of solving problems that were previously considered to require understanding. The more interesting question is whether world models, if they existed, would actually improve the failure modes people care about — like hallucination and planning — or whether we'd just get better stochastic sentence machines with an extra layer of abstraction on top.
But that you also gave a win to Qwen on flamingo is pretty outrageous! :)
Tthe right one looks much better, plus adding sunglasses without prompting is not that great. Hopefully it won't add some backdoor to the generated code without asking. ;)
Can a benchmark meant as a joke not use a fun interpretation of results? The Qwen result has far better style points. Fun sunglasses, a shadow, a better ground, a better sky, clouds, flowers, etc.
If we want to get nitty gritty about the details of a joke, a flamingo probably couldn't physically sit on a unicycle's seat and also reach the pedals anyways.
...despite a miss along the Y-axis where it's below the seat, couple oddly organized tail feathers, spokes, the composition overall is much closer to a production quality entity
Opus 4.7 looks like 20 seconds in MS paint.
Qwen3.6 looks incomplete due to the sitting position, but like a WIP I could see on a designer coworkers screen if I walk up and interrupt them. Click and drag it up, adjust tail feathers and spokes, you're there or much closer, to a usable output
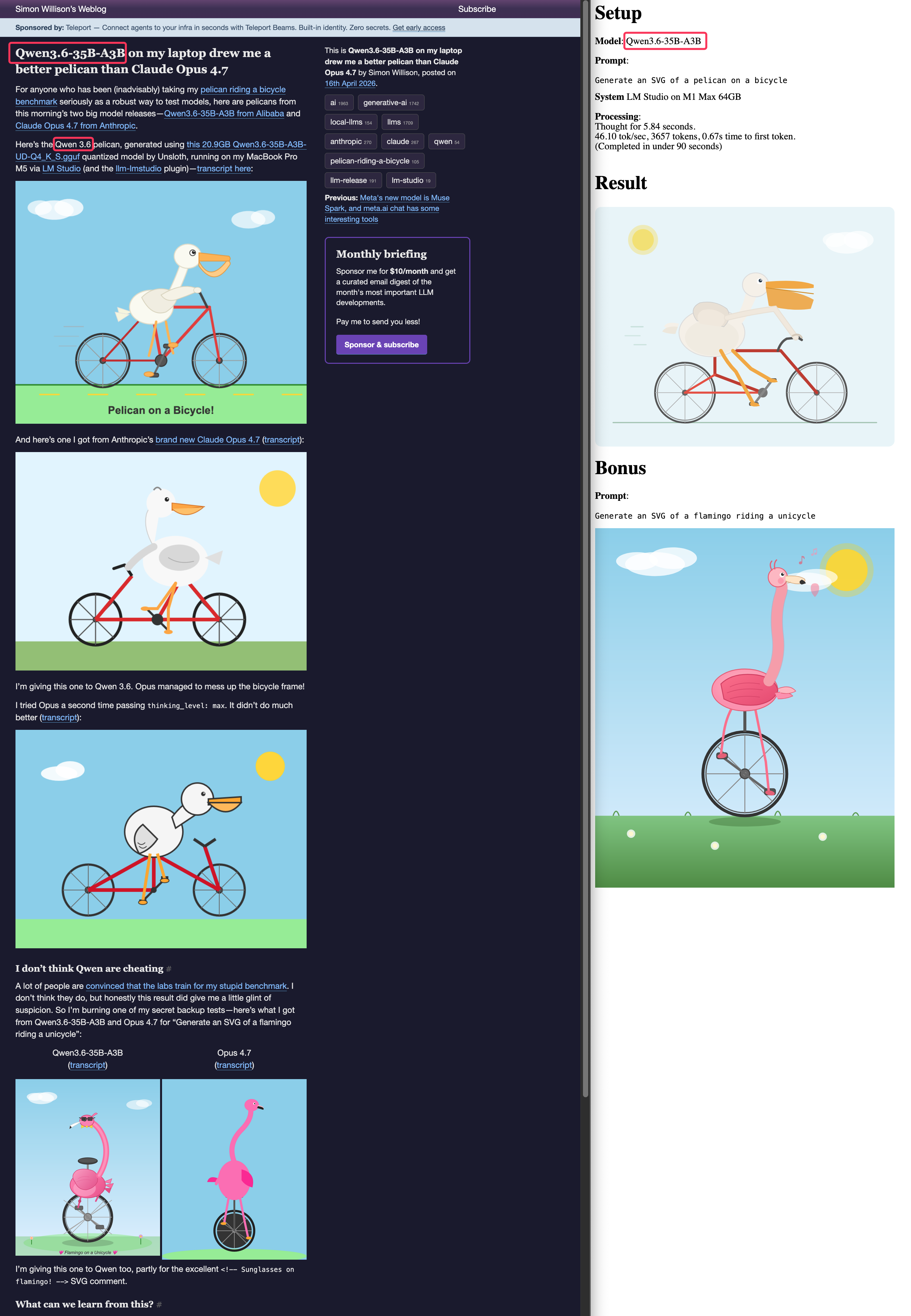
interesting, I just tried this very model, unsloth, Q8, so in theory more capable than Simon's Q4, and get those three "pelicans". definitely NOT opus quality. lmstudio, via Simon's llm, but not apple/mlx. Of course the same short prompt.
Hey I really enjoy your blog. On some things I end up finding a blog post of yours thats a year+ old and at other times, you and I are investigating similar things. I just pulled Qwen3.6 - 35b -A3B (Can't believe thats a A3B coming from 35b).
I'm impressed about the reach of your blog, and I'm hoping to get into blogging similar things. I currently have a lot on my backlog to blog about.
In short, keep up the good work with an interesting blog!
This has happened before with quantizations and other backends (ones not used by the research lab). Give it a week, download latest versions of everything, and try again.
{kind=link}
It drew a better pelican riding a bicycle than Opus 4.7 did! https://simonwillison.net/2026/Apr/16/qwen-beats-opus/