Nah, these are much smaller models than Qwen3 and GLM 4.5 with similar performance. Fewer parameters and fewer bits per parameter. They are much more impressive and will run on garden variety gaming PCs at more than usable speed. I can't wait to try on my 4090 at home.
There's basically no reason to run other open source models now that these are available, at least for non-multimodal tasks.
Qwen3 has multiple variants ranging from larger (230B) than these models to significantly smaller (0.6b), with a huge number of options in between. For each of those models they also release quantized versions (your "fewer bits per parameter).
I'm still withholding judgement until I see benchmarks, but every point you tried to make regarding model size and parameter size is wrong. Qwen has more variety on every level, and performs extremely well. That's before getting into the MoE variants of the models.
The benchmarks of the OpenAI models are comparable to the largest variants of other open models. The smaller variants of other open models are much worse.
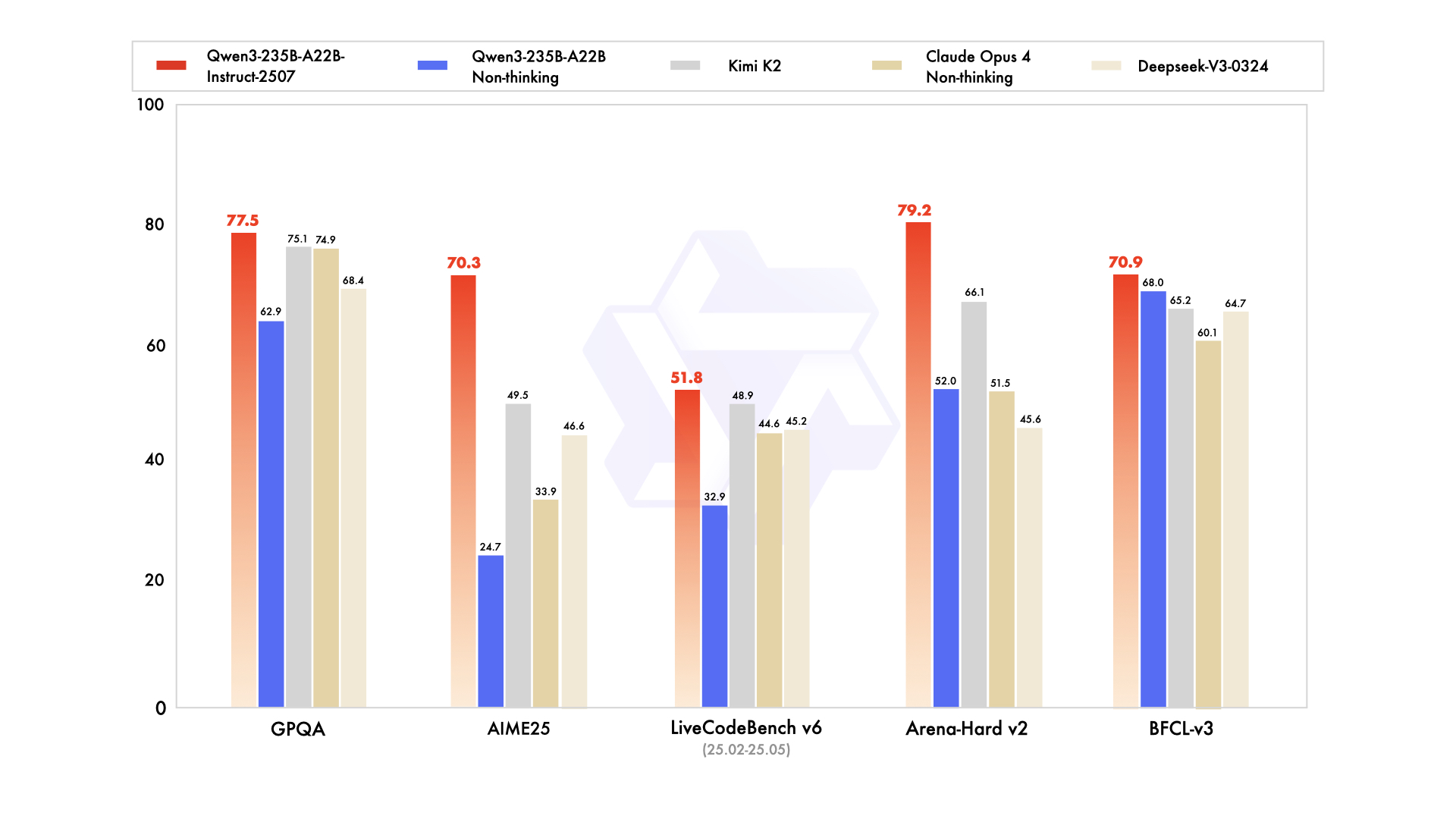
With all due respect, you need to actually test out Qwen3 2507 or GLM 4.5 before making these sorts of claims. Both of them are comparable to OpenAI's largest models and even bench favorably to Deepseek and Opus: https://cdn-uploads.huggingface.co/production/uploads/62430a...
It's cool to see OpenAI throw their hat in the ring, but you're smoking straight hopium if you think there's "no reason to run other open source models now" in earnest. If OpenAI never released these models, the state-of-the-art would not look significantly different for local LLMs. This is almost a nothingburger if not for the simple novelty of OpenAI releasing an Open AI for once in their life.
I'd really wait for additional neutral benchmarks, I asked the 20b model on low reasoning effort which number is larger 9.9 or 9.11 and it got it wrong.
They have worse scores than recent open source releases on a number of agentic and coding benchmarks, so if absolute quality is what you're after and not just cost/efficiency, you'd probably still be running those models.
Let's not forget, this is a thinking model that has a significantly worse scores on Aider-Polyglot than the non-thinking Qwen3-235B-A22B-Instruct-2507, a worse TAUBench score than the smaller GLM-4.5 Air, and a worse SWE-Bench verified score than the (3x the size) GLM-4.5. So the results, at least in terms of benchmarks, are not really clear-cut.
From a vibes perspective, the non-reasoners Kimi-K2-Instruct and the aforementioned non-thinking Qwen3 235B are much better at frontend design. (Tested privately, but fully expecting DesignArena to back me up in the following weeks.)
OpenAI has delivered something astonishing for the size, for sure. But your claim is just an exaggeration. And OpenAI have, unsurprisingly, highlighted only the benchmarks where they do _really_ well.
{kind=link}
There's basically no reason to run other open source models now that these are available, at least for non-multimodal tasks.