Google results have gotten dramatically worse over this last decade. Google now seems to fixate on the most common terms in my query and returns the most generic results for my geographic area. And, it seems like quotes and the old google-fu techniques are just ignored or are no longer functional.
There are a whole host of factors behind this, but I'm certain that the switch to Natural Language Processing / Semantic Search drove this decline.
I have a cat that is always ravenous for anything edible, even if it's not exactly typical cat fare, e.g., my leftover salad, berries, etc. Trying to search for "can cats eat X" after he manages to get a few sneaky morsels is almost pointless. There are so many spammy sites for every value of X, and I have no idea if it's a sophisticated problem to systematically exclude this type of useless content, but Google's top results are chock-full of sites that all seem to follow the format below, where the question is not answered at all:
Is it safe for cats to eat X?
Cats are mischievous and we love them.
X is not typical cat food. Let's go over some background on X before we answer the question.
Cats are obligate carnivores.
Thanks for reading, make sure to subscribe or buy these products!
Yep, this is Content Marketing. People use SEO tools to gauge how good a blog post is going to rank, and the current sweet spot seems to be around 1000 words, so they end up filling it with fluff. Some of those are even machine generated.
The answer to the "can cats eat X", of course, can't be at the beginning or at the end. The reason is that the user must stay a long time and read the text, otherwise Google punishes the website for having a more than acceptable "bounce rate".
Putting the answer in the title (what has been dubbed "Anti-clickbait") also makes the site "less clickable" and will make it drop from the results. Trust me, I tried.
I don't believe for a second that Google's algorithms are unable to identify and remove content marketing blogspam from the results. It must be profitable somehow for the majority of search results to be utterly useless.
> I don't believe for a second that Google's algorithms are unable to identify and remove content marketing blogspam.
Easy for me to believe. They have to use some formula, and as soon as they change it, well, there's a massive industry dedicated to getting around it. If their algorithm is just "filter out what's useless", that's AGI.
Then what’s the point of using Google? In terms of AGI, we have that if Google where to say employ people to look at say the top million searches and heavily penalize junk they could make real headway.
Personally, I swapped to DuckDuckGo in 2019 and have been consistently happier but Bing or whatnot is probably equally valid at this point.
I've used DDG for years now. They give me the exact same results that Google does, all the time. And why wouldn't they when they're indexing the same web sites. Full-text search isn't rocket science, after all, and it's not like new websites with quality content have surfaced lately given the incentives. I don't even bother to cross-check Google's result anymore, something I occasionally used to do maybe two years ago.
That's interesting, whenever I search for anything programming related the results differ greatly and google always wins.
I actually switched to DDG cold-turkey and didn't use !g at all. Until I couldn't solve some problem and someone in my team said "it's the first result on google", I felt pretty stupid then. Since then I've given up and just automatically stick !g whenever I'm searching anything programming related.
I use DuckDuckGo by default but I probably add !g to redirect to Google 2/3 of the time. DDG seems to be a little bit worse about rewarding user-hostile SEO spam [0], but honestly the main reason is that with Google I can use [1] to block those domains. DDG is also still noticeably worse for vague or complex queries IME.
[0] When I search "postgres array_agg" on DDG - something I actually had to search for today - the Postgres documentation is the 6th hit (not even visible without scrolling down!), preceded by crap like https://archive.is/7JeSe. On Google it's the 2nd hit, also preceded by what seems like SEO spam.
I sometimes find myself going to Google for some complex queries or obscure error messages as well, but I'll usually try an alternative query first.
In this case, DDG happens to have a bang shortcut for postgres which takes you directly to the search results on the PostgreSQL site if you query !postgres array_agg.
There's a surprisingly large number of these which end up making it more useful than the generic web search results page overall.
> we have that if Google where to say employ people to look at say the top million searches and heavily penalize junk
I doubt a million is going to make a dent in it. Content marketers are automatically generating this stuff, and Google has billions of users, many of which will occasionally invent a novel query.
The point of content marketing blogspam is to pester the reader with AdWords and the occasional affiliate link.
Old-school useful content is rarely monetized, just someone sharing their passion for something. Occasional affiliate link, with the obligatory apologetic "hey web servers cost money, so I included some affiliate links here!"
The uselessness is just a side effect of Google directing you toward paying customers.
You're thinking of Content Farms. I think the current villain is Content Marketing, which is to attract people to your website without paying for AdSense, via an inane blog post. Like the Michelin guide or Guinness book did before the internet.
The reason Google keeps those results near the top is because it drives up the cost of AdSense, since multiple competitors are fighting for the first page of organic results with those tactics, and AdSense is a way to "cut the line".
The result for users is that the first page of most result pages is littered with advertisement, either via real AdSense or with those inane marketing blog posts.
The other answers are probably the actual reason, but it's amusing to me to think that it's because giving you incorrect results drives up engagement on the search because you keep going back… it's also obviously the wedding metric to use in this case, but that has never stopped people before.
I use DuckDuckGo and haven't used Google in years, but searching "can cats eat asparagus" shows three answers above the fold just in the snippets without even needing to go to the page. Yes, they can, apparently, and it's perfectly safe. No ads in the results, either.
The reason for that is that no professional Content company has made content for "can cats eat asparagus" yet. If this ever pops up on SEMRush or SEOMoz people will start making pages for it, and the results that don't get clicked will be driven to the second or third page.
I have a continued interest in the gopher on steroid that is the gemini protocol.
It makes it hard or impossible to have non-static content, and css do not exists. navigation is a bliss, only or obedient bots are talking.
Bing is the clear winner here, "Can cats eat asparagus" produces a nice H2 "Yes" followed by "According to 2 sources", then two side by side paragraphs with the "yes they can" and surrounding context right at the top of the results page.
I'm honestly such a huge fan of the Bing widgets, every time I see a someone google search for something basic and need to dredge through all of the AdWords laden blogspam, while I know bing has a good widget in your face widget with the answer, I can't help but feel confused at all the "Bing bad Google good" rhetoric.
Some of my favorites:
Annual Weather charts: See chart with monthly breakdown of temperature & rainfall for any location along with record temps, days of rain, and configurable units; Google has something similar but it presents the first few rows of a table first, with a separate tab for charts, and then the charts don't have nearly as much data (avg hi/lo, inches of rain, hours of daylight (bing doesnt have hours of daylight, so +1 to google for that))
Random animal fact cards: Try Binging something like "marsupial", you get a beautiful hand-crafted info card. There isn't one for every animal, but it's clear thought goes into creating them and they always make me happy to see for whatever reason.
A commenter deeper in the thread mentioned the example of
can cats eat asparagus
I tried Google search, and produces a semi-useful snippet at the top, and reasonable results afterwards. Can you share what search you ran that had very bad results?
Can cats eat asparagus? ... It is neither toxic nor dangerous for our cats to consume in very small portions, but neither is it truly beneficial to them. Cats are obligate carnivores. Unlike dogs, who can and do eat everything they can wrap their jaws around, cats tend to be much more finicky eaters.
Can Cats Eat Asparagus? - Is It Safe For Cats? - ExcitedCatsexcitedcats.com › Blog
Feb 12, 2021 — Vegetables, including peas, carrots, and asparagus, are safe for most cats to eat in small quantities. However, remember that your cat isn't going ...
Interesting Facts About... · Which Vegetables Can I... · Is Asparagus Safe for Cats?
Can Cats Eat Asparagus - Cats Dogs Blogcatsdogsblog.com › can-cats-eat-asparagus
Oct 18, 2020 — Although there are benefits for giving your cats asparagus, the potential risks are far much dangerous and outweigh the benefits. It is therefore not ...
Why Do Cats Like Asparagus? (And Is It Safe?)betterwithcats.net › why-do-cats-like-asparagus
The short answer is that yes cats can eat asparagus in small amounts without any problems. But while asparagus is quite healthy for humans, your cat really doesn't need to eat it.
Can cats eat chocolate? Yields ovrs.com (Oakland vet), purina, webmd, thesprucepets.com (cat blog run by vets), pdsa (pet veterinary charity)...
Can cats eat grapes? Yields top-N dangerous foods for cats listicles from various sites such as pet insurance and cat food brands. A response from a veterinary trust is in the top ten.
Can cats eat paint? Yields all reputable medical sources for the first several hits.
I’m not sure I can square this with your description of ubiquitous spam swamping out useful information.
> Google's top results are chock-full of sites that all seem to follow the format below, where the question is not answered at all:
Huh, I just tried this with a bunch of stuff and the snippets for each of the top several results for each all had fairly direct yes/no answers with reasons. Don't know if I got lucky hitting the right food items, or if it's a personalization issue.
For my cat, I'd probably just call the pet poison line in my state/country. Dogs are relatively better at eating human food (except very obvious well known examples like alcohol, grapes, cooked bones etc) but most plants can be poisonous to cats, so I wouldn't risk it.
In addition to plants, common human drugs like alcohol, THC and caffeine are also poisonous to cats.
Also common human spices such as salt, garlic and onion can be toxic too. Cats tolerate very small quantities of these (e.g. small slice of salami), but feeding your cat a chicken with garlic sauce is probably a bad idea.
For pretty much any product or review related search I just do "<product name> reddit" and then scour the somewhat up voted posts for information. Have to deal with tons of dead links though for any post older than a couple of years. The Web really seems like it's an awful place. The original dream of hyper links is really dead. It's all about jumping from walled garden to walled garden through tricks and luck.
1. Search "<product name> reddit"
2. AMP page loads
3. "See Reddit in... App or Browser?" banner w/ grayed out page. Tap Browser.
4. Click through the AMP page to the real Reddit page.
5. Second "See Reddit in... App or Browser?" banner w/ grayed out page. Tap Browser.
6. Fail to read the majority of comments, which are hidden by New Reddit.
6. Manually edit URL bar to replace "www." with "old."
7. Read the comments.
Google is having trouble determining the date of reddit posts and is also making their filter rules useless. You try to filter last month, a result says 3 days ago and you click, but reddit says it was 2y ago!
Use the Teddit frontend (https://teddit.net/) and the Redirector extension (https://einaregilsson.com/redirector/) to redirect all Reddit links to Teddit and view the content there. You won't be bothered by pushes for login again.
This in no way absolves their god awful mobile experience but if you're logged into Reddit with the new UI turned off or use the Old Reddit Redirect add-on it's basically as if nothing on Reddit changed since 2011.
I mean there's not nothing you can do. You can still grab the source to old Reddit and it's just a matter of gluing the old UI to the new API like all the 3rd party clients do.
Not trivial by any means but there's a lot of prior art floating around you could pull from.
Sure they could pull API access and be more hostile to scrapers but that's the current escape hatch for people who would have left because of the redesign.
Their mobile website works fine for me, or at least the annoyances are a blessing because I spend less time on it. The one thing I do notice is if you follow a link out of reddit then go back, it shows an error instead of the thread and you have to reload, which loses your place.
That, and don't get me started on their search. Love getting 0 results on initial submit, then reloading the page with the results magically appearing...
Also love being redirected in order to continue reading certain threads
Yeah. I had decent karma or whatever on a ten year old account and got banned for not having an email address. Shrug. Pretty much killed my reddit habit.
Google today limits how much of "the web" (their index) they will let you see.
You are only seeing what they choose to allow you to see.
Google, not the user, determines "relevance" and Google automatically excludes results. in theory this sounds useful. In practice, Google is now limiting max number of results to 200-300 or 500 if you add &filter=0. Retrieving 501 search results for a single search is not allowed. Sorry.
Try a search for some common phrase like "the web". Surely this phrase occurs on more than 500 web pages. Yet Google will limit you to only 231 results. Does that represent the entire www. Then you try "repeat the search with the omitted results included". Google then limits you to 466 results. WTF. What if you searched page titles for some string. Is every string you search going to be found in less than 500 pages.
Google search results today are not representative of the entire www. Not even close.
IMO Google Image search has gone down hill significantly too. Getting full pages of pinterest results was bad enough but now on my phone you have to scroll past multiple screens worth of Google Shopping ads or images tagged with the "Product" icon before you see any actual, organic photos of the thing you're looking for.
Google Images now only returns maybe 1-200 images by default, and if you click show me more, it shows a few hundred. The top results are consistently pinterest garbage, or similar types of spam. Images are consistently diverse from what I've typed in, and results seem curated to show a diverse types of results, which, given the small number of returned relevant images, means I rarely find something that looks like what I'm looking for.
What I've discovered, though, is that what google images now does, is it is only returning a few results. If you click a result, then there's a "new-to-me" "related images" section that shows images similar to THAT image, only in that window. It is in these images that I actually see the results I was expecting to show on the main page.
Its still far worse than google images 10 years ago, but not as bad as the UI makes you believe by looking at the initial results page.
For my money, yandex.com now has the best search results.
Beware though, yandex allows NSFW by default. You have to enable safe/family search. This is the opposite of Google and Bing, so it could get you in trouble at work. Those crazy Russians.
Not just for images. Bing seems to be a lot more closer to what Google search used to be a few years ago. Anything related to torrents or streams is pretty much impossible to find on Google. Any news not spouted from mainstream sources, gone from Google. My default search deck nowadays is a mix of Bing and DuckDuckGo.
it's nice to see my vague worries, bothering me in the back of my head put into words. Also good to know that i'm not crazy for thinking googles results are surpisingly poor and generic. I sometimes get the same feeling using google that i get reading a poorly transalated manual from a Chinese company. Generic, admire the fact some effort has been made, little laugh inside. Except this is google (and ironically, the chinese copywriters are probably using Transalate)
Yandex is CRAZY good. There's a Firefox plugin that lets you reverse image search from the right click menu, and it opens a tab for Google, Bing, Yandex, Baidu and TinEye. Yandex is the king every time.
Indeed, recently I tried Yandex for the first time and the results were way better for everything I had to search in the past 2 months since discovering it.
One I just recently discovered is symbolhound.com. It's nice because it lets you search for characters that google absolutely refuses to treat as search terms. I needed to debug some makefiles and bash scripts the other day (not my strong suit!) and it helped me understand some of the weird syntax I was seeing.
As others have mentioned, Google no longer respecting literal search terms has made it much worse for many types of searches. DDG had been great at this, but sadly has been following in Google's footsteps the past few years.
You too eh? Over the past decade I've gone from loving reddit to actively avoiding it in most cases, but if I'm looking for specific info on a niche topic, adding "reddit" to a search is often the only way I can get real content written by and for real human beings instead of SEO spam.
Sinister twist though: the SEO crowd has gotten wise to this. I've noticed recently that they've started throwing "reddit" into their spam as a random keyword.
I absolutely hated when they did remove it. I was able to sort of mitigate it by adding "forums" and "discussions" to search terms but it is not the same of course.
Amazon search is similarly broken. Try to find an ECC DIMM on Amazon. Everything I try results in dozens of listings for non-ECC DIMMs. Even searching for " ECC" doesn't work all that well. It's sad that in these days of advanced neural networks, we can't get a simple binary attribute matched correctly in search results.
I guess it's location based too (like Google is). Searching for "ECC DIMM" returned a bunch of actual ECC memory chips available to ship overseas on the first page of results on Amazon.com, though I'd still suggest being more specific when searching for ECC RAM myself (eg. RDIMM or UDIMM or...).
I did, and that helped a little, but it's just sad that what should be a solved problem by now isn't. Nearest neighbour search is so not helpful to me in many cases.
There's a common thread in every one of the good sources of search information: user curated content.
Usually: voted on/curated by members who are specialized in some way (reddit, so, hn, wikipedia to a degree).
The fallbacks are editorial sites.
If you make a search engine that focused on indexing user-curated sites + results outside of that that are themselves curated/voted-on by your search engine users (ie, you and others could upvote axios and Amazon as a good source), I think you'd have an interesting model. Basically, take the HN/reddit model to search itself.
This is the essence of what Google implements. Links between sites are a form of user curation, user behavior (clicks, read throughs, bounce rate, etc.) are like inferred votes. The problem is, everything is gameable. Marketers abuse reddit as well, it just isn't quite as profitable as ranking #1 on Google. If a major search engine implemented a voting model, it too would spring an entire industry of "optimizing" for rankings via upvotes.
You can search Reddit from DuckDuckGo by adding '!r' to your search terms. This is how I search most of the time these days for the exact reasons you mention above. DuckDuckGo has many other bang shortcuts like that too, like '!w' for Wikipedia. Actual search engine results are too manipulated, but they make great link aggregators.
Note that "!r <foo>" is different than "site:reddit.com <foo>". The former redirects you to reddit's own search, the latter keeps you on DDG but restricts the results to reddit.com.
I prefer "site:reddit.com" but honestly it's only because I'm used to it. I search in-app on mobile frequently (which I assume is the same as the on-site search) and it's generally pretty good. It usually finds something for me but sometimes using an external search engine works better.
Occasionally I open a private window and try browsing the web on my phone or laptop without an ad blocker. It doesn't take long before the autoplaying videos and Taboola crap makes me close the browser.
Product vs Product -- I hate those generic websites that compare everything to everything. I am absolutely sure that Google can detect and downrank them. Why doesn't it? Maybe most users like those links, and Google is happy to oblige by keeping them at the top? In that case, I suppose, I should blame the mass market taste rather than Google.
I think the future of search is in finding trusted results, such as those upvoted by reddit or HN or SO, assuming the upvoting system is robust enough to withstand spambots etc. The question is whether a big enough fraction of the population actually care to get good search results.
What really astonish me is they sometimes give me straight up malvertising fake domains, like “general-<word>-info. xyz” second or third from topmost these days! wtf.
You are absolutely correct. So many of the top results are basically machine-generated pages, perfectly optimized for search robots, not so much for humans.
1) Bring in tabbed search result like Cuil search used to have. Easily lets you go to similar/variant topics from UX POV and must be a good way for a search engine to learn what people want more.
2) Add a 'dont show this site' option. So they can easily see when people get annoyed with a result and use that as a ranking signal against search terms. E.g. if people press that for a particular KW but not usually Google knows they got that result wrong and if people press it for almost everything you know its a site people dont want to see. And at a personal level its great to custom remove stuff, like when Pinterest was dominating so much a year or so ago.
Oh yeah, try finding honest product comparisons and test. It is spam or "aggregated tests" on shopping sites. latest examples: cameras and tires. Cameras worked reasonably well on youtube (required some diging to get the "influencer" stuff out of the way). Tires required going through various forums. because every single video or review for tires I was looking for was product placement, spam or both. in the end price and availability decided the tire question. sometimes I miss the times when you had magazines catering for a certain domain doing honest tests and reviews. Well, even back then magazines started to prefer Canon over Nikon or the other way round.
My experience is puzzlingly contrary to the unanimously-shared frustration above.
I tried this with a bunch of products ripe for spamming: instapot review, nvidia 3070 review, and Apple Watch review, and the first page results were almost entirely reputable.
I also tried “huggies vs pampers pull ups” and the result is quite a good variety of forum threads, blogs, and reputable articles. “Quasar formation” leads to Wikipedia, but also academic articles and astronomy.com. “How beer is made” is even better quality.
Is most of the web junk? Have I gotten astronomically lucky in not finding it? Are these somehow the exceptions that prove the rule?
(Ironically I think my search terms caused this comment to be flagged as spam..!)
The results are better when the products are more common/famous (Nvidia card, instapot) since there will likely be reviews from The Verge or something that rank highly.
It's less common stuff that tends to give you mostly crap.
I haven't heard of Axios before - how would you characterize it? Looking at the website I can't quite tell if it's an aggregator or how they generate content, and if there is any particular leaning to what they host.
I get better “ Product vs. Product” and “Product Review” results with ddg these days.
Once I took the time to read one of the sites and it’s obvious it’s generated content, and awful at that. I still reading pros and cons of one of the product and the same thing was mentioned under both, just with different wording.
GPT-3 or similar is going to make this way worse.
The only time I still use google (via !g on ddg, what an awesome feature) is to search for local info or in native language. But even here ddg is getting better, especially if I append the name of my city or country.
I tend to do that too. But for product reviews, I am certain that the fake review problem will hit Reddit soon, if it hasn't already. This technique is way too common, and manufacturers are going to start including Reddit in their fake-review spam just like they do with Amazon reviews.
Quora can be good too, my go to is usually "question reddit", and if that is not sufficient then "question quora". Quora is spammy too though, so it is hit or miss, but when it hits, it hits good.
A lot of us Quorans were putting real insight there. Seriously. First few years was amazing.
As they wound down the top writer program, which is really where the "hits good" seeds are, they decided to pay people to ask questions.
Signal to noise ratio began to trend toward unfavorable. But traffic shot right up!
There have been other decisions contributing to the Quora we see today, but the paid questions really had the most impact in my view.
That said, yeah. There is still a lot of high value contributions to Quora. They are just a little harder to find now.
One thing I feel they missed the boat on was the credits system. Early on one could accumulate those and use them as a sort of currency. I "spent" some of my pile asking specific people for insight and it worked out well. I had others do the same with me.
Basically, one could get to a domain or subject expert and the site was still "family", so it would lead to a high value exchange.
For a little while, their text question UI hinted at what a Quora could be. Well connected Quorans could toss a question in via SMS and get solid responses back, sometimes quickly.
(Came down to follower counts, writer status, and a few other things)
These options were not abused much that I could tell and they hinted at a means to query people without draining said people, and or everyone participating having some give and take.
Was a fleeting moment, but one I ponder from time to time.
I would subscribe to a "group" that has the UX and overall dynamics of something like what I just described right.
It's infuriating when Google prefers the documents that ignore some of my keywords even when there are plainly pages that include them all. I get the sense that there's an over-weighting of broad semantic match, to the detriment of lexical match, in their current ML model, whatever form it is now. It's harming quality for a segment of technical users like ourselves but might be "better" in the aggregate over all users, according to at least some of their internal quality metrics.
Back in the 90s, search engines were driven largely by sparse vector representations of the documents such as TF IDF vectors before latent semantic indexing, topic modeling, and other dense vector representations like sentence embeddings entered the fray (not to mention non-content features that use the web graph, click stream, etc.). A lot of NLP applications use a mix of dense and sparse features but it's hard to get the balance right in a way that works for all inputs. Google's pendulum has swung too far in the "dense" direction, as it certainly seems "dense" a lot more often lately!
I don't think the "problem" here is bad search results -- I think the lack of clicks is thanks to search results becoming much richer. The "card" style answers that show up more and more often mean I don't have to actually visit the site where the information originated (which publishers despise, for good reason). Take a common search I made last year as an example, "covid king county" -- I almost never ended up visiting the county's coronavirus dashboard because Google had the graphs I wanted in the search results.
I think it's a popular opinion on HN that Google search sucks, but I just don't agree. I used DDG on all my devices for the better part of last year, and bailed when I noticed by g! usage ratcheting up.
It sucks at searching for exact things, it would often subtly by essentially change the meaning of the search. Like confusing searches for the desired "weight of scooter" with the max "weight of rider" on the scooter. What a shame, it was even a shopping related search, where the money are. They could have led me to a sale.
When people are trying variations on a search it's a clear sign of failure. They should do something about it, like use a verbose natural language interface or select a different strategy for ranking or enable the exact in-depth mode. Apparently the NLP community can do natural language Q&A in papers, but Google can't do it in search.
Other pain points: searching in depth all results on a query, not just the top skim and remembering context between searches.
And Google Assistant itself is too poorly integrated and dumb. Where's the GPT-3 like language skill? So many TPUs what are they doing all day long? They have more text and images than any other entity on the internet, Google bot has been sucking it up for so long (not to mention links, keywords and clicks). It should show in the quality of their AI. It's a shame to have OpenAI steal their thunder like this.
Yeah, the parent and most its children are focusing on something not even related to the article — this is about providing what the user is looking for without the need for more clicks.
While it’s an unpopular opinion on HN, there’s no denying that from a user perspective, that’s only a good thing.
I definitely read this like the two of you. If the information being shown by Google results is what I need, there isn't a need to click further. On top of that, many of us have been "trained" that products like ZScaler are going to block most sites and register a hit with InfoSec. I'm not going to click on bobsfunmainframefacts.com if Google scraped the needed info for me.
Card results might be a good thing overall, but they certainly aren't only good. In many cases, adding the cards takes revenue away from the exact people who collected or created the content to make them possible in the first place. We'll never know how many websites shut down or never got created to begin with given Google's history of crushing the revenue from various sites on a whim.
It can be simultaneously true that Google's gotten better at displaying results pages that fully satisfy the user without the need for a click, and worse at other kinds of queries.
The latter case -- searches which I have to rephrase, or that cause me to give up on the search entirely -- adds to the total number of searches that do not lead to clicks.
It drives me crazy how Google never fails to remove the most unique and yet most important words of my search term. It basically does this 99% of the time now.
> It drives me crazy how Google never fails to remove the most unique and yet most important words of my search term. It basically does this 99% of the time now.
Which is ironic, because one of Google's original innovations was to make a space an AND connector instead of OR (which its competitors used to maximize result counts). Back then, they understood that fewer, more specific results were better.
"Three wrong ideas from computer science" - Joel On Software, August 2000 says:
"when the big Internet search engines like Altavista first came out, they bragged about how they found zillions of results. An Altavista search for Joel on Software yields 1,033,555 pages. This is, of course, useless. The known Internet contains maybe a billion pages. By reducing the search from one billion to one million pages, Altavista has done absolutely nothing for me.
The real problem in searching is how to sort the results. In defense of the computer scientists, this is something nobody even noticed until they starting indexing gigantic corpora the size of the Internet.
But somebody noticed. Larry Page and Sergey Brin over at Google realized that ranking the pages in the right order was more important than grabbing every possible page. Their PageRank algorithm is a great way to sort the zillions of results so that the one you want is probably in the top ten. Indeed, search for Joel on Software on Google and you’ll see that it comes up first. On Altavista, it’s not even on the first five pages, after which I gave up looking for it."
I wonder are they doing this because of a resources issue; do including all the unique words put too much of a hit on their servers and it's way cheaper to give generic results?
I'd prefer to recognise immediately that there are no results & reframe my query that to start to scan down through the results, maybe click into one & start to read only _then_ to realise it doesn't relate, back to Google — "oh, they didn't actually search for what I told them to search for" & then reach the same point they could've given me at the start.
At least there should be a checkbox for "make a best guess when limited results" / "give me my exact search query" (maybe there is somewhere & I've missed this)
> At least there should be a checkbox for "make a best guess when limited results" / "give me my exact search query" (maybe there is somewhere & I've missed this)
There is, one of the drop-downs gives you the option of "all results" or "verbatim".
Google's search index of the web of 2021 sucks. Getting two search results which match the exact terms I got is no longer particularly strong evidence that those were the only pages with those terms, and quite a few times I've had it fail to find pages which do exist and should have matched the search I did.
I find it really obnoxious that if I search on 5-6 terms, Google will return popular results that include 1-2 of the least specific but most popular terms. If I put anything in quotes, it will ask if I really mean something less specific than what I put in quotes! Well yes if we get to a generic enough level, you will return the best relevant results to those generic terms. Who cares if they relate to the specific search I started with?
Google results have gotten dramatically worse over this last decade.
A lot of people say this is because Google is worse at returning the desired search results for various reasons (algos, ads, spam, etc). I've come to suspect it is more deliberate on the part of Google.
I've said it before, so I'll belt out the chant again: "Google doesn't make money from providing the right search results. Google makes money from keeping you searching for the right search results."
This is especially true for the vast majority of people on the internet who do not know there are any (better or worse) alternatives to Google.
And another reason, Google makes money when you click on low-quality machine generated search results, because these pages are almost always monetized with google ads. This causes a conflict of interests: when they improve search, they earn less money.
I’ve seen it: I happened to enter exactly the same query from two separate IPs used by communities without deep cultural connections in between, and only one of them returned the desired results.
That felt like a thick wall of glass separating worlds have suddenly come into my view.
ooh yeah, especially when I am doing some specific database programming stuff and my results come up with amazing perfect resources and a noob's results come up with absolute shit... its bad.
Same here. I can remember how refreshing it was when Google was new and you could trust it to give you results for what you actually searched for instead of what it thought you searched for, like AltaVista and the rest of its competitors were doing at the time.
I guess it's time for something new to do the same thing to Google that it did to those companies years ago.
Other sites still offered old-school website directories, I remember using those for years, well after Google became #1.
I'd much prefer going back to something like that now than bother with Google's approach; depending on the search term, I already know what the top sites are going to be, and I know they won't have what I'm looking for.
> Google now seems to fixate on the most common terms
This feels very true... the majority of my searches go like this:
1. Search with all relevant terms with some parts that should be exact combinations in quotes => nothing or BS results
2. Remove words that Google is fixating on without context => no or seemingly unrelated results without search terms at all
3. Reduce specificity to 2 or 3 words, topic and subtopic (trying to locate context only and search the rest myself) => sometimes ends me on sites where I can then just browse for the result i'm after
4. Worst case reduce to single search term to find huge context sites and manually search myself. Sometimes at this point I just give in and manually navigate to other sites where I know I can manually browse and narrow down context myself and then try to find what I'm looking for... it really feels like a curl web scrape and grep would work better than Google at this point (yes I know google "site:", it's doesn't work properly anymore).
I was kinda thinking the same too until I went back and gave bing and DDG a shot and well, Google is still way better for my searches. I think its more of the seo spam that popping up thats making the results look less useful.
That would be an interesting problem, how do you algorithmically filter out SEO and focus on useful information? A signal vs. noise problem, but on human text, with the added challenge that the noise is trying to outsmart you. Maybe an adversarial ML network with an SEO-generating bot working against you?
Dramatically worse... if that's true, then I wonder how good they were a decade ago. Because every search I've done today produced the result I wanted on the first page of the results, above the fold.
I can't say I've really counted how many days that's true. I can't even say that I really remember what searches I did yesterday or the day before. But if I'm not totally weird and google searches were dramatically better in the past, then they must have produced the desired results every time on almost every day.
Default search might have gotten better, but it also became virtually impossible to do any complex queries. Google is being too smart and it's extremely hard to find old results, foreign results, other meanings of a popular keyword. It's always trying to force you to the same results, whatever you try. Oh, and if it's anything you can buy you get loads of ads followed by spam.
> every search I've done today produced the result I wanted on the first page of the results, above the fold.
Same for me, but that's because I just stopped searching for things that I know will not give me good quality results as they used to be circa pre-2010 back when search tools like +, -, and "" still worked and the results weren't filled with generated SEO texts.
> Dramatically worse... if that's true, then I wonder how good they were a decade ago.
Oh, I forget some people doesn't know why Google enjoy their current position:
Back before 2007 they completely blew competition out of the water:
If something was accessible on the Internet and wasn't behind a noindex spell, Google would find it.
Compared to other search engines that both then and now work more like Google does today it was totally amazing.
Then things started to go sideways:
- first there was: did you mean <something else with similar spelling>? (this was actually user friendly)
- then there was: we didn't find many results for <search term> so we included <related but different search term>, use double quotes to search for "<search term>"
- then there was fuzzing: expnding all my search terms into the unrecognizable unless I double quoted them
- and the latest few years they have also ignored my double quotes
somewhere in between there they messed up the + operator that used to mean "make sure this term is included" as well as ~ that used to mean I wanted Google to fuzz that term.
Sometimes I can get better results by trying to think how my wife would phrase the question, i.e. instead of searching for
- <search terms including a weird mispeling from a dialog box>
I search for
- <why does my computer show search terms including a weird mispeling from a dialog box>
somewhere in between there they messed up the + operator that used to mean "make sure this term is included"
IIRC this one was driven by Google Plus marketing wanting "+" to mean "Go to this page on Google Plus" so they could do some co-marketing thing with +Pepsi.
You can't even compare it anymore, as the web is dramatically different now than it was a decade or so. Just the amount of blogspam that has accumulated in those ten years, all caused by Google's ad-meddling is enough to drown out the minuscule amount of "unique" or "good" content that existed back then or is being currently created.
I'm really starting to prefer DuckDuckGo at this point. There was one time when I thought they would always live in Google's shadow, but in this brave new world of content censorship and commercialization-induced bias, I find that I get noticeably "better" results on the more neutral alternative.
Anything in google that hits the political "twiddler" does not produce useful results. This was in the Zachary Vorheis leak of Google internal documents.
I wish DuckDuckGo actually found the stuff I'm looking for. I've given it a solid try a few times and it's just not as good, and I can't justify spending twice as long as I need to on a search.
Google doesn’t want people to find alternative sources for news, healthcare, and politics. They now force all the mainstream sources to the top, regardless of whether the search terms entered have any relation to the actual results. And this seems to have carried over to other subjects as well, because I can never find obscure pages any more.
This should destroy Google, but for some reason it doesn’t, and it baffles me that they are still surviving in this.
This is has been my experience as well. When I search using very specific terms for a any topic tangentially related to something popular, all I get is the News articles.
I suspect it is because the best sources of information do not serve adds, but news, spam, and social media do.
Same could be said for any site that is smaller in scale than the #1 result.
If I'm looking for a review of a Yeah Yeah Yeahs album, I will see links to Amazon, Pitchfork, Rateyourmusic and other sites well before I find something written by a regular person on their personal blog.
Same goes for products. I will see a page of Amazon links before anything on say, a boutique Ecommerce website with a Shopify backend.
Thank the media for slandering the company, accusing it of perpetrating genocides, political strife, Russian election hacking conspiracy, etc... The reason they do this is being scared of liability, not a top-down desire to control.
I was trying to remember the name of a song. Not an obscure song: "Toe Rag" by The Rifles, a modestly well known indie band. I even remembered a chunk of the lyrics! But I got nothing. Here's let's cheat, and copy and paste exactly two lines from the song.
For me Google "verbatim" is the best way to get focussed results although it's too bad it doesn't allow date ranges. Bing search with appropriate use of guotes, + and - operators and date ranges usually beats non-verbatim Google search, and it can sometimes be better than Google verbatim.
The verbatim mode is exactly what most people here are missing. But, for some reason, it's something that can't be configured - you need to set it in every new search. Three freaking clicks.
I don't understand what goes on corporations. I guess power users aren't a target demographic anymore.
I’m suspecting that they generate results from statistics ahead of time and just serve you the closest cached result, unless it is strictly necessary to do an actual search.
> For me Google "verbatim" is the best way to get focussed results although it's too bad it doesn't allow date ranges.
One word of caution: I use verbatim mode and I regularly (but not always) get Wikipedia clones as my top result. It must be skipping some of their anti-spam filtering.
For coding questions it still works relatively well. For "reviews", or anything remotely tied to commercial interests, it's indeed pure garbage: pages and pages of low quality links.
> Google results have gotten dramatically worse over this last decade. Google now seems to fixate on the most common terms in my query and returns the most generic results for my geographic area. And, it seems like quotes and the old google-fu techniques are just ignored or are no longer functional.
I thought the main issue here was Google directing searchers to its own services and scraping data from non-Google websites to present on its own pages? It's declining search result quality is certainly an issue, but I don't think this link is about that at all.
It really depends on what you are looking for. If you are searching on a term that is used by business you will get mostly shitty content. But if you search for things that make no money, for example. "diff with prosemirror" or "travelling with monitors" you will get very relevant results.
I don't think it has a lot of to do with new search algo. I think it is the opposite, the algo is mostly the same as a decade a ago, but now it is abused by SEO expert. And Google doesn't seem to care yet
yesterday I was trying to figure out how to look up the nameservers of a domain including the vanity/parent nameservers using a tool like nslookup or host, it took me a good 10 rephrasings before i found a stackoverflow post answering the question, and not just a tutorial on how to set up vanity nameservers at X registrar/hosting company
So there needs to be a significant cost in production of the content - youtube for example - want to see how to (a recent example) lay laminate floor, well you need to have a camera and a person and, hell, a room with laminate flooring needed - that's a big cost.
Lowes has made a video, so have dozens of contractors. It's amazing how tool rental firms have not advertised on there ... actually that is a bit weird...
SideNote - for some reason I replied to an email outreach from Rand, and he actually replied back within a few hours, clearly having read my words and come up with a real answer.
I was frankly shocked. Either he works an inhuman amount or he has secretly invented AGI to respond to his emails for him.
Yeah. I wonder what fraction of searches actually end with no clicks, just the requestor bouncing from the search results page. Anecdotally, I suspect that metric is also trending in the wrong direction.
You are 100% correct about the switch to Semantic Search and dense vectors being one of the main reasons. BERT shouldn't be anywhere near my search results.
Google results in the past year or two seem extremely odd to me. I see less results than I used to, I see more of the same sites than I used to, and a lot of content that I try to find that I know I used to be able to, I can't.
Oh, and then there's a bunch of weird links that come up to obvious content generated by AI being peddled. Odd.
Probably a side-effect of SEO[0]. Its in the best interest of the vender, not of the user. I should be banned, forbidden of fought against by google themselves.
And the natural language questions sometimes get stuck. For example, [what's the difference between cauliflower cheese and cauliflower mornay] seems like it should return a page that tells you what the difference is, but it doesn't. It returns a bunch of recipes.
The highlighted responses to suggested natural language questions are comically bad. Answers to different questions, complete failure to apply simple contextualisers like 'today', and treating some random on Quora or some splog as an authoritative source for identifying a fact that has authoritative sources. I know it's difficult to do this stuff without human curation, but it's like a campaign to discourage people from taking NLP seriously.
Don't forget AMP. I accidentally typed google in the url and decided to use it to see how's it going after so many weeks of not using Google. Got redirected to a blank page with AMP's frame which instantly reminded me why I no longer use Google for search.
I got so annoyed with Google that I set my default to duckduckgo and/or Bing, but now I've gotten in the habit of switching back to Google constantly, because once I am directly faced with the quality of the other options, they suck.
I have noticed an eerily accurate prediction of my search term though. Several times, when I hit a bug and attempt to learn more about it, Google makes precise auto-complete suggestions
We are in this situation because people never wanted to pay anything on the web, so we have become the product. That's the price to pay when you want everything for free.
>I'm certain that the switch to Natural Language Processing drove this decline
It's the switch from lexical/syntactic search to semantic search. There are benefits and drawbacks to each and it would be nice for Google to give you the option to try each.
My guess is that you're part of an unprofitable long tail. Why optimize for your use case when they can capture customers that bring more money with far less effort?
I wager that most people don't perceive a decline in search results quality. At least not to an extent where they'd notice and switch to using Bing.
Google Search users aren't Google's customers. Making Google Search useful to its users is not what makes it profitable. It only needs to be mildly better than the competition, so that people use it and can be used for collecting data and serving ads.
So GP may not be "an unprofitable long tail". GP may in fact be "a profitable typical long tail for whom Google Search is frustratingly unhelpful".
I'd be surprised if there was a long tail of customers. There is probably a long tail of searches for most customers.
Google giving up on difficult searches and focusing on showing promoted links, AMP sites, and "rich" result boxes is probably a sound business strategy too, and is unlikely to make users switch search engines this late in the game (Bing/DDG don't seem to do better anyway).
Many moons ago, I put a ton of work into a (now defunct) content site that provided specific information in a small vertical. Each post took hours, but I enjoyed writing the articles, and the revenue from the ads was enough to enjoy a little extra cash every month (we're talking just about enough to cover a car payment, for context).
Google decided they liked a lot of the content and started providing it in their knowledge graph. It was initially great to be validated and the link to my content at the top of the search result was pretty cool to see. But it did tank traffic, as Google scraping my content and giving it away at the top of their search result page meant people didn't need to navigate to my site.
Felt pretty terrible, if I'm being honest, but I also have always subscribed to understanding the risks for relying on other networks for my own benefit.
BUT!!!
As a regular user of search engines, I love getting the answer super fast without necessarily having to guess what sort of ad-trap I'll have to navigate to get the answer I'm looking for on some random content site.
As a user, when I'm asking some non-critical question, it's nice to just get a snappy answer. I appreciate it.
The problem of course arises when content creators stop making the content for Google to scrape and index, what then?
In my experience, "Google Instant Answers" are more often than not factually incorrect. It makes me queasy every time I see that... it speaks volumes that's so much more important to them that they keep you on the page that they'd rather give you wrong information than let you go.
For those that are curious it displays a Quora answer that states:
>Thomas Running
>Running was invented in 1612 by Thomas Running when he tried to walk twice at the same time.
It's actually quite and interesting post if you follow the link. Obviously it's not correct in the purest form but there is justification for this answer.
What I find entertaining is that while answers may be wrong, you can see from the question statement and the returned sample text that it is working perfectly in a mechanical sense. The parsing of the question is correct, the searching works, and so does the ranking. But at the end of the day, it is just applied NLP at a large scale, not AGI, so it doesn't know that it is returning a wrong answer. It doesn't know anything at all!
That wrong info came from the pages which are listed in the search results. So much objectively, factually incorrect info is written in to blog posts which show up in google search results which then get copied to instant answers. Particularly historical info is filled with mistakes, people misunderstanding the context of some old news article and then taking it out of context to drop on wikipedia where it is taken as fact.
The error usually arises from Google misinterpreting and decontextualizing the page’s content, for example reading a table incorrectly then giving one stat as another stat. The page is correct, it’s Google that’s wrong.
> The problem of course arises when content creators stop making the content for Google to scrape and index, what then?
This has already happened. People put content on their sites only long enough to figure out what works, then turn that content into a book that can be sold. Every Cal Newport book came out of his blog posts.
Others are turning content into paid newsletters, courses and Patreon-only walled content.
Wrote something 15 years ago? Just set the "Date Modified" to last week and Google will think it's been updated.
The 'content' you and I are seeing are just second and third-hand summarizations of popular topics written by content marketers.
>Wrote something 15 years ago? Just set the "Date Modified" to last week and Google will think it's been updated.
...which is awful! Try searching for historic information on a viral topic and the results are littered with incorrectly dated listings that may satisfy the search criteria but are from the wrong time span.
It’s hard to see how this isn’t anticompetitive. Using their market power in search to show their own ads but prevent anyone navigating to view any others seems like something that should end up in court.
Google has always respected robots.txt and has well documented how to restrict crawling.
I don’t see it as anticompetitive so much as copyright violations. The fact that Google makes advert revenue using this strategy just contributes to damages.
Anticompetitive would likely require Alphabet (and potentially other companies) from preventing users from accessing the original web page (which might be possible but more difficult to prove).
Now I’m curious: what would happen if someone had no idea that Google existed (insert wild reason here. I’m leaning towards lived in the woods for 40 years and self-hosts content without reading anything, like a hermited author)?
Does Google still get to say “everyone knows we scrape your content” and “We have instructions about opting out”?
My take is that if you serve web content to unauthenticated clients, you must expect humans and robot users will look at, remember, and catalogue your content.
To the extent that you want to control your content, you need to take measures to do so. Reject unauthenticated, assert copyright/trademark controls, or do some basic searching to implement open standards which most/all legal agents adhere to.
The thought exercise is moot if you consider how many laws people are governed by in the modern world that they don’t know about but are still expected to learn and abide by. Also worth thinking about what recourse you expect this naive website owner to be able to effect given they have done the absolute minimum to protect their content.
I feel like it might be dangerous to equate Google with societal laws, but you have some compelling arguments.
If I may counter to flesh this out:
Take books. Authors have copyright laws to protect the content but they also have to accept that humans will look at, remember, and catalog the content of their books.
And we ended up with libraries which catalog on a large scale, as well as laws that dictate how people can use the content of those books (especially when they do borrow them).
But Google could be considered as a company that borrows all the books, has people transcribe and file them, returns the books, and then advertises that they are “better than the library” because they have hired the best and fastest librarians in the world. However, they charge a cover fee. (In reality this fee is paid by advertisers, but it’s still there and Google is still a for-profit company)
I think that it would be hard to argue that that type of business is reasonable or expected, and to bring it back to the example of a content creator: I think many of us would push back if a reclusive author brought a manuscript back to the city after 20 years of being a hermit, had it turned in to a book, and then found out that every single person who read it did so without paying him, without him being able to connect with those readers, and without him even being able to know how many people because this for-profit library chose not to tell him.
You can absolutely copyright the packaging of facts (see any textbook ever printed).
Google often has entire paragraphs ripped from the underlying page in their knowledge graph. Would it be copyright infringement if Google displayed paragraphs of text from copyrighted textbook? If so, is there a difference between doing that and doing the same with, say, "facts" from a blog post?
IANAL, but my understanding is that an individual fact can’t be copyrighted, but an organized collection absolutely can be.
The example I remember is that A baseball game score can’t be copyrighted, but if you run a website that lists all of the baseball games throughout history and you gathered that data and did work to organize it (other than to scrape it from another collection), you have a claim to a copyright.
Did they scrape your content and put it into their own database? That is, if you had deleted all of your content, would it still have appeared in the Google results?
I'm pretty sure Google is rather quick to delete dead listings, but their is a twilight period where pages persist in results. This is especially annoying with forums hosting dead and un-archived links.
Will content creators stop, or will a new payment model that isn't "pay for eyeballs" arise?
The financial sources for information-collection-and-creation undertakings throughout human history have been manifold (wealthy patron and collective financing, to name two). It is entirely possible, if Google finds its data sources drying up, that Google itself will pay for data collection (they already do this with several categories of data they host).
If Google ever started including copy-pasteable code from Stack Overflow, I might never follow a link from Google again.
Which I think says a lot about how Google is used now. I don't use Google to find web pages, I use it to find an answer to a pressing question. When I'm looking for something to read, I go to a content aggregator like HN or Reddit.
Of course this isn't sustainable. If Google is just presenting other sites' data "for" them, and thus depriving them of traffic and revenue, eventually there won't be any incentive to create the content Google is scraping. Long term, this seems self-defeating for Google, just as its ruinous to the sites they scrape.
But so few people use DDG. It probably isn’t much of an issue for stack overflow. If Google started doing that, my guess is that stack overflow would feel it.
> eventually there won't be any incentive to create the content Google is scraping
It's an interesting hypothesis, but it assumes the only reason people bother to seek and aggregate facts is to get paid (and the only way to get paid is click-through to ads). No doubt that early surfacing of data could disrupt payment-for-visit-dependent models, but that doesn't guarantee the data evaporates from Google's view or that new payment models don't arise to replace the old.
I don’t particularly like the press, but as a profession they recognized quickly the danger of Google displaying directly their content on the results page. Too bad they fought only for themselves and not for the web in general, since they’re holding enough power to tip the scale.
I don't see any reason why Google can't pay for using your website's content on their search engine. Looks to me exactly like the same deal they've been cutting with media owners from Australia & France. The law should cut this side too. For individual content owners as well.
Generally the price of information is race to the bottom, people shouldn't be expected to get payed anymore. I'm happy to pay for content: I pay for Youtube and Netflix, and they pay content creators. I'm also buying books on Kindle. But when I signed up for the Economist, what I read was significantly worse content than Hacker News comments.
You don't have to put your content on google, you can add yourself to robots txt and google will respect that.
You want to be able to force google to take your content, AND force them to pay for being forced to take it.
A better idea would be coming up with plans on how to break up googles market share to split it among multiple smaller search engines which may allow you to bargain for paid content with.
The observation is that Google makes money from eyeballs on ads. The reason they make money is that they can lead people to the content that they want.
The content that they want comes from websites, which benefit from the traffic google sends their way. If Google stops sending traffic their way, they won't block google in robots.txt: they'll simply shut down, because they're not making money off the eyeballs on their site.
So, it's a symbiotic relationship: Google sends traffic to sites. Sites send their contents to Google. If Google tries too hard to keep eyeballs on their own ads, then they become a strangler vine on their own ecosystem, depriving it of the resources that it needs to grow.
There needs to be a balance between the traffic that it sends to sites, and what it surfaces directly on the SERP.
The value of any individual site on google is quite low, there are plenty of other sites to use. If a significant number of sites decided to pull their content from google and make deals with bing, google would reconsider how they operate.
There is no need to have governments force companies to pay each other when they are free to share content or not share. The government should however ensure there are no monopolies which prevent this kind of action.
You missed the point again. This isn't about forcing anyone to pay. This is about Google strangling their ecosystem in exchange for some short term growth.
The OP post was about having governments force this exchange. If you are talking about google optionally taking part in it, I'm sure the finance people at google are capable of working out when its worth it on their own.
Maybe they should have to pay, especially when doing things like extrapolating content for knowledge panels, but the Australia law has a lot of problems due to the extra provisions (plus that it's applied arbitrarily and not based on criteria)[0].
+1 to this. Weather, translations, timezones, quick math, sports scores (searching “nba” gives a much cleaner interface than going to nba.com), not to mention Wikipedia snippets. That easily covers >50% of my searches.
Google's goal, for a long time, has been precisely this experience.
The company mission statement is "Organize the world's information and make it universally accessible and useful." Nothing about that statement says "redirect web traffic to third-party sites." They consider it an inconvenience to the user (a negative signal) if the user has to click through.
I suspect a bunch of people might jump on the bandwagon that this is Google repackaging others' content into search snippets and robbing their sites of traffic.
No doubt there's some truth to that, but I'd like to indulge in a slightly different flavour of Google bashing on this occasion.
The reason I often don't click through on search results is that the search results are garbage - either irrelevant or poor quality. I'm in the midst of refurbing and redecorating my house. Often I'll need to do some research on topics related to that, and when I do that I often find I need to refine my search query to find anything of relevance, even sometimes digging through several pages of results manually to find a really useful page.
And then there's work: I still haven't found any answers on this, but one of the things that's on my mind about becoming a more senior business leader is that I feel like I'm changing as a person. I feel like the way I think about problems and people is changing. That's to some extent to be expected, but the issue is I'm feeling ambivalent about some of the changes I perceive.
So it's about the effect that leadership has on the leader (selfish, I realise).
But when I start searching around this topic, what does Google want to show me? Pages and pages of results about change management or, when it's being marginally less of a village idiot, pages and pages of results about leadership styles and changing leadership style. Neither of these is what I'm talking about.
A human will understand that, but Google doesn't, and I'm finding that increasingly to be a problem when I'm looking for information: either, (i) my results are overwhelmed with low-grade spammy SEO'd to hell and back content, or (ii) Google's AI is too bloody stupid and pig-ignorant to understand what I'm talking about.
Hence I don't click through on the search results the majority of the time.
I'm seeing very similar issues. Google seems to heavily favor sending people to the sites with the highest content volume instead of the highest quality content.
The worst thing is that content creators are manipulating this to build content farms full of low quality content and overwhelming ad volumes.
I miss the old web where Google was really great at finding that one guy's blog post that was actually useful.
That's a tall order - Google doesn't know the quality of the content, only how popular it is. Right now it's based on data science pooled from existing search result clicks, but originally it was based on the amount of backlinks each site had - so instead of user viewership and satisfaction, it was dependant on the amount of nerds at the time who had already found the site/article useful. The internet has grown enough to mean that everyone else vastly outweighs nerds in terms of backlinks and clicks for any particular topic.
> about becoming a more senior business leader is that I feel like I'm changing as a person. I feel like the way I think about problems and people is changing.
Dunno, but this might be the sort of perspective you're seeking: there's a book https://en.wikipedia.org/wiki/Moral_Mazes about the culture of managers at large corporations. And a series of posts on it -- I'd start with the one near the top that's just quotes from the book, to see if it's you're after: https://www.lesswrong.com/s/kNANcHLNtJt5qeuSS
This seems like... a really big deal? I know that we're all sort of living in a world where "put ads on your high-traffic site" is a deeply outdated revenue model, but it's still quite a popular one, depending on what corner of the internet you're in.
I think that model is as relevant as ever. Google is just narrowing the list of “high-traffic” sites worth putting your ads on, to exclusively Google properties.
If I put an ad on there, but nobody clicks it, how is that still relevant?
Anecdata, but the rate at which I google something that I basically want to search on Wikipedia but then don't click through to Wikipedia has got to be about 50%. WP doesn't monetize their site, so maybe not the best example?
I guess this could also be indicative of how people use Google (the search engine proper) now. You need some sort of data(phone number, address, trivia fact), and Alphabet has already scraped the relevant site to pipe in that data.
I tried 5 different diseases, 4 had wikipedia on the first page, 1 had it on the top of the second page.
Do you mean blocking just that automated text result that appears on the top of the page for some questions? That would make sense, since they probably don't want to boldly state medical facts without context, especially since that feature can be wrong sometimes.
Disclaimer: I work for Google, not on anything related
No I meant the result itself, but I see it too now, I thought they were blocked altogether. I don't know if it is changed or it was always just never/rarely near the top (and maybe that legitimately organically happens).
Searching 'ADHD' and Wikipedia's extensive page is midway down the second page of results. Drug ads for amphetamines from Google on 3 or 4 of the first page's results, but not the top few results (which are CDC, NHS, etc.).
I'm confused by the top comment using this headline to complain about the quality of results. The quality of results is obviously irrelevant to the fact that most searches do not result in clicks. Google specifically tries to answer your question on the result page:
"nifarious" - oh, it's spelled "nefarious"
"1000 USD in CHF" - aha, about 1000 swiss francs
4 tablespoons in cups - 1/4 cup
"how old is taylor swift" - 31 years; this shows up in the suggested search dropdown, so you don't even need to hit the result page
>The quality of results is obviously irrelevant to the fact that most searches do not result in clicks.
Disagree. It's completely relevant. There are two reasons why people do not click on search results - either because they got the answer directly from the rich snippets (like you suggest), or because the results are so trash that you need to now perform another search to narrow the results further.
This is what I was going to comment. Aside from all the tools like weather, converters, timers, etc..., google has even gotten good at pulling content out of articles so you don't need to click. It displays it in the search results.
For instance, searching something like "what is the most common car color" shows me an exerpt of the answer from a article on automobilemag.com without having to click and read the whole thing.
5-7 years ago, I would've had to click and skim through an article.
Moreover, Google compiles independent lists of their own. Searching "what animals mate for life" or "movies tomorrow cruise has been in" will pull up an interactive list. No click-through required.
Google has become a really bad search engine for anything besides the most superficial information about a broad range of topics, especially ones that are commercial in nature (which it is extremely good at... go figure). I spent a while trying to find the name of a contemporary artist whose name I forgot by querying those key words along with various things about the thematic etc qualities of their work and all Google could tell me was about Claude Monet. Gave up and searched some of the same keywords on Twitter of all places and instantly found the artist I was looking for.
I've had similar issues quite a bit recently and have resorted to trying other search engines. Sadly DuckDuckGo, Bing, Wiby.me (!) and others aren't really better.
Good search was historically one of the harder unsolved problems on the web, even back in the 90s. The problem is that nowadays we treat it rather like a solved problem when in reality it's still probably one of the harder unsolved problems on the web.
The thing for me is DDG results aren't worse either though. I'd much rather support them than Google. Very often when I use the g! modifier to redirect the results aren't much better.
It seems people have a pretty mixed experience here. I trialled DDG for several months back in 2019 but switched back to Google after I found myself using !g for almost every search.
> 2/3rds of Google Searches Now End Without a Click
Isn't that the whole point of Google providing it's own interpretation (sometimes several of them) of an answer to the search query ahead of the classic search results: give users what they are likely to be looking for without requiring another click?
> zero-click search problem
As a user, I see zero-click searches as a benefit, not a problem. It's a problem for people trying to use Google as a “clickstream” to waste my time and try to get a crack at my money, but then, that's exactly why it is a benefit to me.
Often I'm looking for a Wikipedia page, and it seems that in the past year or so Wikipedia pages have been moved way down on the first page of search results, especially if the topic is a medical one.
This is effectively the same as the "wiki [query]" search shortcut you can add to a browser. This is useful, but there are also situations where I want to get to the search engine's results page but weighted towards the wiki content. Wikipedia search will always send you to the page for an exact match. There are times where I want to see the search results instead.
Anyone have any opinions on the state of image search? What do you use?
I find Google Image search, which I used to love, filled with absolute garbage now. 90% of links are to Pinterest which greets you with usual overlays, signup modals etc. I use DDG's image search because I find Google's search unusable.
Also, Yandex image search is probably the best reverse image search on the market. It's crazy how much better it is than Google.
It's not that google isn't capable of providing much better search. It's that they are driven by interests other than the users actually doing the search. Google has some of the most advanced tech and engineers in the world. But they also have an endless list of issues they must address - no facial recognition, no racial bias, no sexual content, filtering specific politics, supporting partners, etc.
They also face huge amounts of legal pressure to make GI less useful and stripping out features so that more people follow through to the site and see the adverts.
DDG is ridiculous with resolutions. Categorizes 500×900 resolution as "Large". Otherwise it works for me as an image search engine. I usually return to google if I absolutely can't find what I'm looking for - google is better when it has to guess, with instructions like "yellow blob old game".
Google provides instant answers for most medical queries, calculations, celebrities, sports, news, weather, how-tos, definitions, reviews, map, shopping, images, etc. Most people don't search outside of queries that google can answer from their own sources frequently so this seems plausible.
Those instant answer cards are often wrong. Perhaps more troubling are the instant answers Google gives you but you aren't aware they are wrong. It's the Gell-Mann Amnesia.
Considering 2/3rd of searches end there, I wonder how many people are walking around with false information that Google fed them.
This type of "no-click search" is infuriating because of how often people take the snippet Google spits out at face value, without the context that a full article might have provided.
Could someone here shed some light on the possible copyright implications of how Google now rips excerpts from web pages and displays them directly on the search results page? A cursory search shows that there have been a few lawsuits in the past[1][2] but they seem mostly related to the act of indexing/caching web pages and the display of thumbnails.
However, Google's new method of extracting and displaying possible answers to queries from external sources instead of simply linking to those sources feels like it falls outside of the bounds of fair use.
Most material they're scraping is copyrighted, and reproducing it without permissions would be prohibited save for the various "fair use" provisions.
Google would probably make a "de minimis" defense of the practice. A previous case (Kelly v. Arriba Soft Corporation 2002) allowed thumbnails in search engines as fair use, but that's not quite the same. And current interpretation seems to be pretty restrictive on what's insignificant enough (witness various music sampling cases). And while any individual result may be small, doing so on an industrial scale is probably not "a trifle" and harm can probably be demonstrated. Ultimately, it would have to be tried to tell.
They might also argue implied license. In cases like meta tags, that's probably reasonable. For straight-up scraping, it's more questionable.
About a decade ago or so, I remember complaining about Google's search result quality having already declined then. Specifically, I think my complaint was that the search results were a lot higher quality in the mid-2000s, and then from then on, the search results ended up becoming progressively more sanitized and crafted.
So, I mean, we're way, way past Google's heyday. It's not even close. But it's interesting to me that I can recall having those discussions that many years ago, and that people still complain about the same issue today.
In fact, just about every other search engine is better in my opinion.
All of my Google searches have now ended. I use DuckDuckGo exclusively, and while there was a time when I used to add !g to about every tenth search, I have not felt that need more than about once a week for several months now. DuckDuckGo is simply enough improved, and Google enough worsened, that it's not worth it anymore. From my point of view, Google has blown the vast advantage they had, and is now second-best.
The author speculates that this is a direct side effect of Google searches being monetized by ads, and therefore targeting multiple searches.
I don't think that's the case. I think this has more to do with the fact that Google now deliberately surfaces as much information - including summaries, answers, tools and widgets - in the search results page itself, which incentivizes searching without a subsequent click. Google very much wants you to end your search journey on google.com, but I think that's because they believe it will keep people coming back. I do not think Google directly tries to keep people searching for the same thing.
This may still raise interesting antitrust concerns though.
I think this is mostly due to the immediate messaging they give on the topic that is sufficient and no further click is needed. Meaning the little drop down suggestions more often than not for me has the full content I want. For example, "What is the meaning of temporal?" or 'Who wrote "Wild Thing?"'. Google has inline calculators and an amazing array of usefulness without needing a website to go to in so many cases growing more and more. What is kind of sad/funny about this is its making the search results themselves less useful in which it was built on, giving less incentive to give this AI food.
I think the issue here is really simple. Google has learned that it is more profitable to infer the intent of a query & tell people what to think up front based upon a carefully crafted set of advertiser criteria. It is difficult to appease your paying customers when you give the non-paying customers direct access to the most likely match for their query and allow them to draw their own conclusions from the information.
Put differently, there is a conflict of interest inherent in the very nature of Google's business. It can only become a steeper death spiral from here if the motive continues to be profit above all else.
So are we trusting similarweb's data on Google itself? How trustworthy is it? How do they get their data? I've seen similarweb be off by magnitudes vs alexa for estimating traffic on some sites I own.
I don’t have a Mac. Does Spotlight handle units as well as Google does? Also, doing the calculation in Google is handy because it’s easy to share in a modifiable way.
Wolfram Alpha is pretty good and is more powerful than Google Calculator, but I’ve found Google Calculator to be more responsive and consistent and thus a bit easier for regular usage.
I don't know how well it handles units vs. Google but it does convert as you type, say "5inches" immediately shows it in cm but you can keep typing "5inches in m" and it'll do the math too.
Yup. Weather, stocks, various bits of statistical info like GDP and population, and image searches. Image searches are super awesome for learning some things in ways you didn’t expect.
- I'd make sure that multipurpose sites get lower ranks, ecommerce with a blog would get worse rank than a stand alone blog or an ecommerce. this would eliminate all the content marketing and owners would have to focus on their core business
- I would put a cap on amount of content that increases rank. A website with a million recipes harvested from other sites won't be better than a blog with 10 quality recipes.
- I would downgrade rank for use of third-party cookies, invasive ads etc.
- I would give users an option to "mute" a website
- Randomise top results to make sure no one can "occupy" top spots.
It should be noted that Google (applies to other search engines) searches aren't just web searches anymore. Rather Google is frequently used as knowledge engine similar to WolframAlpha albeit not in that level (yet). Specifically a click-less Google search can be:
spell checking (term "wrng wrd")
dictionary (term "define word")
word translation (term "random in greek")
calculator (term "1+1")
unit conversion (term "1m in ft")
weather (term "weather tokyo")
sport scores (term "uefa scores", or ufc, nba, ...)
map instructions (term "instructions to nearest city")
For fun search any of the aforementioned terms alone (besides the first one) and with term mentioned in parentheses. Also lots of searches return card information (e.g. "spell checker" or "Issac Newton") or snippets which are seen when searching for instructions. That is when searching something encyclopedic where one-line summary or some simple instructions will suffice means someone will not go ahead and open Wikipedia or any other site.
If I put content out on the web with no login, then thats what I do.
If I want to control the revenue then I use a different protocol.
I can also just simply set up a robots.txt file telling others what to do with it and lots of indexers, Google included, respect and abide by my wishes.
When people misuse a tool it seems easily fixed by them properly using the tool.
Trying to change the web because I’m too stupid to understand it seems like a bad thing.
Are you like frequently traveling to different cities based on the covid level? Is your behavior somehow changing significantly due to slight differences in covid deaths in your city?
I now use google as a last resort. I start on DDG or Bing and go from there. If those are dead ends, I will reluctantly use Google as a means of last resort.
There are so many ads and now every time I search for something on Google, the first five results aren't even related to what I'm looking for. You search for "hifi headphones" and you get eight of the top ten searches are something like, "The top 10 hifi headphones." in an article from three or four years ago. Or "What you need to know about buying hifi headphones." informational articles. Not to mention the obligatory Amazon product link stuffing at the top of any product search results.
Google's results are just so convoluted, its a real PIA to try and wade through everything they're advertising in order to get to an actual product or manufacturing website these days - I just gave up a few years ago. Too much advertising and not enough organic results to be useful anymore.
Not going to change, since Google has become a huge advertising container with less and less value wrt genuine information about products.
If I search for a product to buy, I usually add the "price" word to it so that the search engines includes shops selling that product. All fine, but if I want to read reviews (real ones, not the usual paid fakes) or blogs in which a product features, compatibility etc. are discussed, which is very common in IT hardware, I don't want Google to throw at me a pageful of its top sponsors. No thanks, I don't care, I'm perfectly able to find a place where to shop; what I want from a search engine depicting itself as intelligent is to know when I want technical information and stop defaulting nearly every damn result to a shop to buy from.
This is what Google has been trying to do, right? As they keep scraping more and more information out of the sites that they index and then provide thumbnail answers in the results page, there's no reason to click on anything.
If I google for the weather in Chicago, I'm not going to click on a link to weather.com for it, because the seven day forecast is right there.
If I google for information about a person, Google scrapes Wikipedia and puts that right in the results page sidebar.
Flight information, bus schedules, anything that looks like a calculation, a whole bevy of other things, Google just preempts any results and shows inline at the top of the search page. Why would you click through to anything?
This is going to be happening more and more as technologies like GPT-3 get better and better.
I remember seeing a demo which accurately answered a lot of search questions like who killed Mahatma gandhi, etc just using the GPT-3 model(1). I'm sure Google must have even better models than this and it only makes sense for them to answer the questions directly when there is sufficient confidence level.
A lot of time I get my answer in the “people also ask”section of the google search result. The section has exactly the paragraph with the relevant information. Maybe, search results are getting better?
It's actually something good (expecially for Google) since the information found is now usually in the results itself instead of inside a website.
If you notice, in the last years, Google shows you lists extracted from articles, makes calculations directly, answer simple questions like age, shows a lot of Wikipedia info for any person/movie on the right, etc, etc.
It's not because there is more ads or because the results are irrelevant, actually I'm never disappointed by the results.
It’s not all bad. I consider it a feature that Google usually pulls the right information from Wikipedia. It doesn’t harm Wikipedia, which is free anyway, but reduces their bandwidth load.
That's not strictly true. Wikipedia is crowed-sourced, and losing visitors means losing potential contributors.
You could probably make the case that someone who would rather read the snippet on Google isn't likely to contribute, but it likely has an effect on the margin.
And that's ignoring the donate banner they throw up there from time to time.
Article says clicks to other Google properties don't count as clicks. I would be curious how many searches end up in a click to YouTube. I know my fraction has gone up over time as it's more likely someone has put up a video about some finer point of one of my hobbies than it is they post a blog. At least in these cases the content creator can often still monetize these searches.
Do AMP clicks count as no click since the user didn't leave google?
And how many are no click because google has presented semi-correct but not really correct information at the top of the results so the user finds what they think they're looking for without actually clicking?
Seems like google is doing just fine so I'd imagine both of the above scenarios account for a significant portion.
Google's zero-click answers are really good, especially if I search for a fact.
While it's true that this is possibly killing sites by preventing traffic flow, it's one way to battle content padding for the sake of grabbing traffic.
It might be an interesting move if Google were to pay a small fee to sites whose information was useful for a particular search, like those I chose to expand.
Search is the most important application of AI inside Google. It's the raison d'être for data collection.
So why the search quality decreases?
My current hypothesis is:
Users who click ads and generate ad revenue like this garbage. Google learns to serve this outlier group of users. Killing the experience for everyone else is just a side effect.
looking over the comments here, people seem to be assuming this is because of googles scraping and presenting of data on the search results page. but knowing my experiences with google search over the past few years, I immediately assumed this was because google search is getting worse and worse every day.
after reading the article, the author doesn't correlate the findings with a cause, so who knows what the real reason for this is. but I know for me at least, it now takes me 3, 4 or 5 searches to find an abstract with something that looks even close. maybe I such at google searches, but after doing hundreds a day for over 12 years, I feel google search just got reaaaal shitty some time in the past few years.
ddg use to not even be close to google in result quality, now, imo, they are on par with each other. and that is largely due to googles decline, ddg only got slightly better.
This seems like very good progress. I'm continually impressed by how fast I can find the answers I'm looking for from Google. Google is working hard from being somewhere to get pointers to places that might contain the information you want to giving you the answers directly. Truly amazing.
That doesn't surprise me. I look up answers to questions and definitions of words using google and seldom click through because I get what I need in the results. Not sure that's 2/3 of my usage of Google but that may not be far off.
"love monetizing niche search engines and other data products, but it looks like Google will eventually get into any industry where the main source of traffic is organic search, I wonder what is next."
Today I was working on an old project and I had to create a tfsignore file. I only got links to gitignore, even if I added 'TFS' as a keyword. In finally ended up directly searching SO and found the Microsoft documentation.
That's definitely a tendency that you'd expect when sites are engineered for engagement and everybody starts out at google. I guess it also means google completely controls the experience of most people on the internet.
I wonder if you'll see more domain specific content aggregators/search engines pop up as people (like myself) because increasingly dissatisfied with the almost populist nature of a lot of Google's search results.
This "panel" must be highly biased, right? Only Google itself knows the real answer to this question. The data in the article comes from 100 million people dumb enough to infect their devices with malware.
> Only Google itself knows the real answer to this question
This alone should be setting off alarm bells for everyone, the government should be raiding Google offices to find the necessary facts to answer these questions. Google operates as the de facto front page of the Internet, the default starting point for the vast majority of the public, and they're incredibly dodgy about the real facts about how they use that power.
It's incredible how often Google both states a "fact" that is extremely biased in their favor, and simultaneously suggest it's indisputable because only Google has data on it, and of course, Google will not share the data because it's confidential business information.
This stonewall is behind incredible lies like the idea that targeted advertising increases revenue by 50%, despite independent data finding the difference closer to 4%.
I think the issue at hand here, is that Google should be legally compelled to disclose the real answers to this question, and a lot of other questions about how their algorithms work.
> The data in the article comes from 100 million people dumb enough to infect their devices with malware
This is ironic, considering the Google Toolbar, headed by Sundar Pichai himself, is much of how Google got it's mass adaption as well as browsing data to improve their search rankings. Perhaps the difference between "malware" and "useful tool" is how successful the business behind it is. ;)
I can't get behind this. Suggesting that corporations be raided by the government is not a good idea.
To my knowledge, Google has not denied any information requests they've received (or been subpoenaed for), and actively work with law enforcement in circumstances required of them. If we get to a point where they stand in contempt of court ordered information requests, perhaps this becomes appropriate, but let's not jump straight there because they're a big (huge) company. Many, if not most companies have private information that only they would know about their company and don't have the expectation of turning it over, I don't think scale changes that.
> To my knowledge, Google has not denied any information requests they've received
Your knowledge stops very short in this area then. Google is utilizing the entire playbook to delay and obscure information from antitrust regulators. For example, Google almost always responds to requests for response from regulators on the last legally permissible day to do so, often after requesting multiple extensions. Here's an article about the third extension they got to respond to one of the EU charges: https://phys.org/news/2015-08-google-extension-eu-case.html (Google responded to this one four days before the deadline of the third extension, https://www.wsj.com/articles/google-responds-to-european-uni...)
Each of these months-delayed responses of course, can be summarized down to "Google doesn't believe Google is anticompetitive" in a blog post I could've written in an afternoon.
They managed to drag out the EU cases years longer than they should've taken through these sorts of games, and the US cases are now just getting started.
Essentially what's happening here is Google knows it's in the wrong, and it knows it's making more money than it will ever be forced to give up in fines and penalties, so they want to drag all of these processes out as long as possible.
The public would be best served by raiding the offices, seizing the information, and stopping all illegal operations from continuing while the investigation is completed, so that Google executives have adequate incentive to respond quickly to restore business.
I started to write up a whole thing, but your hn history and linked twitter shows you're very openly rabidly anti-google. That's fine, and in general I'd even mostly agree with you. I draw the line at suggesting government raids of private companies, though. That won't ever be a good idea.
There are a lot of companies I am pretty anti, to be fair. Find me say one nice thing about Facebook. Or Tesla.
I would say in the case of big tech companies, I am concerned the standard playbook is no longer viable. They often are more powerful than the countries that would regulate them, and they use threats and market manipulation to overpower nation states. There are now multiple examples where a company has used withdrawal or suspension of services to force a country to undo or roll back a law, or where a company has outright bought a political measure that repeals legislated protections for individuals.
The sole place sovereign nations still have the upper hand is arguably physical force. I think we need to start looking at some of these companies as organized crime, not civil violators.
Anecdata: I was searching for macOS stuff last week (trying to get something working because Big Sur has changed a bunch of stuff) and, most of the time, the top results where from 2011-15. Completely useless.
As a user: thank fuck i dont need to click through to those piece of shit sites that are nothing but spam and ad farms that front load fake description and title content
It's quite common for teenagers on TikTok to use a screenshot of the often-wrong snippet at the top of the Google results page as evidence in whatever crusade they're currently on.
I admit I sometimes use google search as a spell check that's a simple Ctrl + T away. I'm not proud, but it's so simple to access when you're already in the browser.
As long as they use the content appropriately that’s a good thing as it reduces web traffic to Wikipedia and saves them money.
The purpose of Wikipedia is to improve human knowledge and all their content is CC so unless Google is altering content or biasing searches, sucking it into Knowledge graph seems like one of the main reasons Wikipedia started.
People who create and curate content quite often want to be paid for their work, they create businesses to support themselves, often in the form of a website. If Google scrapes and repackages that content, so the searcher never even visits the creator's site, what incentive does the creator have to continue making content freely available?
google search results are nothing but content farms and other mostly useless shit unless you search for things that are STEM-related or academic-related.
What's disappointing about this is how inaccurate some of the information is. For example, we even go the extra step of adding the OccupationSchema meta tag on Levels.fyi for salary data to be shown on queries. However, Google only uses the base salary component and not the total key, which highly misleads people into taking what's shown as 'per year' as the total compensation, especially since there isn't even a clarification for it on the salary cards.
Still think it does make for a better user experience overall, just wish they'd add these details to some of these Search schemas they themselves adopted for the purpose of getting more pinpointed info.
90% of my Google queries is "Search terms + Reddit".Usually I end up with better quality info. Reddit is missing a great opportunity there, especially because its search engine sucks (They should use algolia or something). If they were more visionary they could use their internal search as a starting point for a generic web searcher.
I use DDG as my default engine on my phone, and about 50% of the time I have to re-search on Google with g! because I'm not finding what I'm looking for.
That's not to say the results on Google aren't getting worse, because they are, but DDG still has a long way to go.
Doesn't DDG do the same thing? DDG will show a snippet from Wikipedia, has a built in calculator, built in timer, and so on...
Sure, Google also has a flight tracker widget, but it's not that much worse than DDG. If you really want no widgets or inline responses, https://www.startpage.com/ has that.
EDIT: Startpage does have a time widget (search for "time in <some place>"), but doesn't have a calculator, timer, or literally anything else. How odd...
I recently realized DuckDuckGo's !sp operator can give you Google results anonymously via Startpage.com
"Startpage acts as an intermediary between you and Google, so your searches are completely private. Startpage submits your query to Google anonymously, then returns Google results to you privately. Google never sees you and does not know who made the request; they only see Startpage."
Monopolies are a barrier to entry. I don't think any of google's products prevent that. As we see in most technology over the last 20 years, the companies at the top can change fast.
A company that creates a better search engine, will easily take over search. Next gen of search will be better at providing more relevant / less spam
Youtube does have some network effect and high costs but not enough to stop anyone from competing and vc money evens out the costs. Next gen in video may offer more features, or for a completely different platform like VR
The only platform I do see them having a strong ability to block out potential competition would be mobile and Android.
Can you provide examples of better companies replacing the incumbent in a mature market? Most examples I can think of occurred in markets that were a tiny fraction of their mature size. Most of Google's users weren't using search engines when Google was created. Most of facebook's users weren't using social media when Facebook was created. In these cases it's less about converting existing users as it is about capturing new users.
Yahoo, MySpace, Geocities were all top 5 global properties at one point.
Spotify crushed several music related services like Pandora, napster, maybe even Apple Music.
Dating sites theres a few as in Match, okCupid have largely been displaced.
>Most of Google's users weren't using search engines when Google was created.
I really don't know about your assessment about Facebook but I'd fundamentally disagree, as in the beginning they were capturing the college aged to young professionals. I'd say they fundamentally grew off the back of MySpace users. Myspace was huge and everyone had a page at the time.
Google was a little different as they did help to define and create this space of web indexing, as a lot of early search pages were more directories and portals.
Since Regan, the US doesn't care about concentration of market power, only whether prices for consumers are affected. Since Google services are "free", no anti-trust violations are incurred under this standard.
However, it's looking like things might be changing slightly. Biden appointed someone that cares about anti-trust. We'll have to see if that's just for show or not like most of his administration.
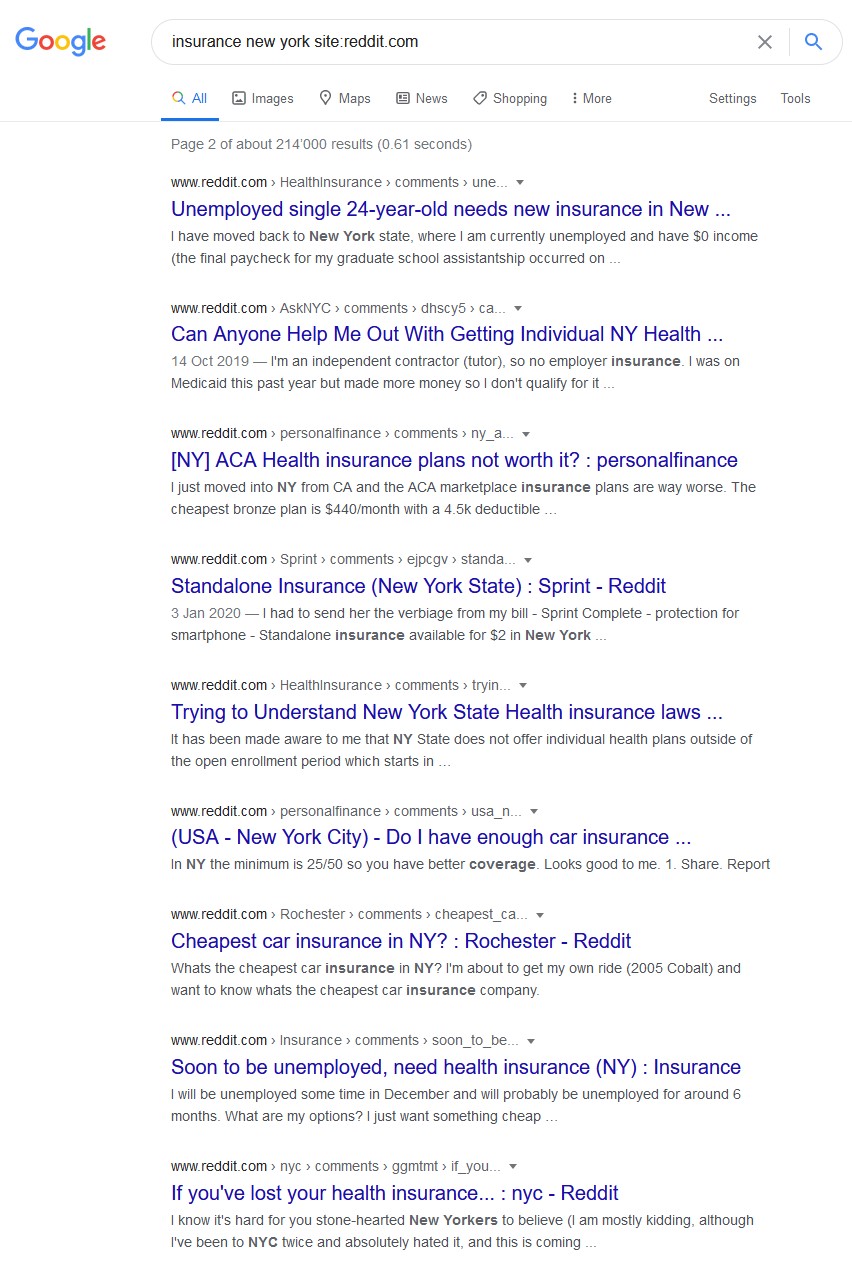{kind=link}
There are a whole host of factors behind this, but I'm certain that the switch to Natural Language Processing / Semantic Search drove this decline.