Everything above. Friends don't let friends use App Engine, and by extension, fringe GCloud services they could break or shitcan at literally any moment
The technology of a vendor is way less important than its culture. So far Gcloud seems to understand that. Maybe the App Engine team is outside that org
> Everything above. Friends don't let friends use App Engine, and by extension, fringe GCloud services they could break or shitcan at literally any moment
Not sure why you think they can shitcan them at literally any moment. Although GCP's track record of deprecation is of course far worse than AWS's, they do make and adhere to promises in their terms of service that, in most cases, they will give at least 12 months before deprecating services which have reached general availability. This includes both App Engine and Cloud Run, minus any features that have not yet reached general availability and minus one very fair documented exception for App Engine.
That’s false. The policy only covers services being turned down. A-la Google reader style. Not api changes. Not forced sdk/software upgrades. Or pricing changes.
It does cover backwards incompatible API changes - read the second link I provided:
>Further, Google will notify Customer at least 12 months before significantly modifying a Customer-facing Google API in a backwards-incompatible manner.
What are you referring to with forced sdk/software changes? Maybe it's the same exception I mentioned for App Engine when a previously supported language runtime goes out of support by the upstream language community?
As for the famous Google App Engine price hike everyone likes to point to, the lower price was only at a pre-general availability launch stage.
You're right that they don't make any specific guarantees that they won't hike prices on short notice, but within the scope of Google Cloud Platform features that have already reached general availability, when have they done that?
If any browser vendor just pushed a trivial standard like
X-Consent: no-cookies
X-Consent: cookies-ok
Sites would have gobbled that header up overnight, and the other browsers would have received substantial pressure to follow.
But it's a missed beat by now, nobody is paying to have hundreds of thousands of web sites updated for such a thing even if it did exist.
Sucks none of the major browser vendors are based in Europe or this might have happened. Meanwhile, I'm no lawyer, it's not clear whether the header would pass the legal test, but I'm sure a sufficiently motivated party might have a good shot at arguing that it did
DNT is too simple, there should be new better standard integrated in web browsers. The never ending popups with absolutely 0 constancy across sites is atrocious, moreover if I rejected a cookie for a domain on site A I will be prompted on site B if I want to reject it again.
For every domain that wants to create cookies, I should be prompted by the browser (like I allow camera access) if I authorize it to do so, we can even imagine that each domain would have cookies purpose information ('mydomain.com/cookies_policy') in JSON that the browser is able to present to the user (describing each cookie of the domain). Then the browser would be responsible to never create cookies that I rejected.
The main advantage would be that in incognito mode I would not have to repeat myself 10 times a day.
If you want to see an example of a more granular policy that the browsers (well, Internet Explorer, but it was the majority browser at the time) implemented also being ignored, see P3P: https://en.wikipedia.org/wiki/P3P
Ultimately the only cookie an users will willingly accept is the sessionid/rememberme. And the "remember me" checkbox is consent enough under the GDPR.
Behing all the legalese and marketing-speach, all the other purposes boils down to :
- We are too lazy to setup a matomo, so we are giving google your browsing pattern.
- FB is forcing us, so we can pay ever so slightly less for ads
- Google is offering to tell us your sex and age
- If we dont track you, we will show you a viagra ad.
- Through 4 intermediaries, we can pay this totaly-objective-blog which sent you here.
I'd love to hear from someone with a complex cookie consent pop-up, but i'd bet there is about 80% "accept all" (because the users have been trained to do it) 19% "reject all", and no-one is mixed.
So the do-not-track would have been accurate enough.
Main difference is that Do Not Track was an industry incentive, not a legal requirement like the GDPR is. They could have made it legally binding, but they chose not to.
Hrm fair point. I'm not sure DNT could have been repurposed to imply consent under much newer regulations, but you're generally right, this mechanism predated the EU regs and somehow was passed up.
"Somehow" is because there was nobody enforcing it, so nobody had any incentive to honor the request. Legislative approach is the only way to have an actual effect.
DNT was also intended to be an explicit opt out. However Internet Explorer enabled by default for three years, giving the industry an excuse to question its validity and ignore it. Privacy centric Microsoft or intentional sabotage?
Nothing, I still use it daily at work, alongside Angular (though not together).
> how the heck did they end up settling on Angular of all things
At Google, It's convenient to use Angular because there are well-documented ways to do all of the normal things you have to do to have a production-quality front-end application, such as building reusable components, dependency injection, component testing, screenshot diffing, etc. Standardization of the framework also has the benefit of making it easier to find someone to ask for help.
It would be a truly herculean task to bring another framework up to the same level of support and integration of Angular inside Google.
As a former frontend dev, current google employee, I don't think it would be as technically herculean as it would be politically herculean. Plenty of production apps aren't on angular, but they are in much smaller orgs with less management, or they are in search where shaving ms of time is a job description.
It's really hard to wrangle the amount of feature growth cloud is experiencing and I expect they made tradeoffs to satisfy that first.
Coming from the outside world and looking (back) in, I simply can't ever imagine being in the kind of environment where discussing the choice of web framework or tool language would last more than 10 minutes, before whoever spoke last basically wins. But then, I'm the kind of techie who has lost their love of and has actively grown to despise tech.
"Is it supported?" "Yep"
"Can we hire for it cheaply? "More or less"
"Does it support the weird InternalSuperWidget it must talk to?" "Essentially"
It isn't this simple. You have millions of LoC already written, docs, onboarding, hundreds of teams with different opinions, training people in a different tech stack.
In green field development or smaller companies, sure, I however do not find it as exciting since there are not real people / technical challenges most of the time, once you compare with what you can build with 1000s of engineers.
I do not miss Google's monorepo one iota. It had huge benefits, but after stepping back far enough the result also easily begins to look a little like Stockholm syndrome. Anything they want to open source they basically have to rewrite from scratch because of that godawful repo, never mind reasoning about what actually ended up in your binary on any particular day when depending on such a gargantuan tree, and of course not to mention what by now is likely 10s of FTEs dedicated simply to managing the tree.
Those millions of LOC mostly only existed to serve their own purpose, and possibly the intrigue of many a doe-eyed eng. If I came across a codebase like that today, I'd likely be quite vocal on reallocating the evidently outsized engineering budget to some more productive use
Can you expand on "If I came across a codebase like that today, I'd likely be quite vocal on reallocating the evidently outsized engineering budget to some more productive use"
Like, Google (or other company) still has to deliver to production and they do so using their existing system. I believe not supporting the existing system means not having deliveries.
I am actually facing a similar issue in my current job and it isn't an easy thing to move away from.
> It would be a truly herculean task to bring another framework up to the same level of support and integration of Angular inside Google.
I left on 2018, and I remember there were a lot of orgs and teams trying to migrate to a new framework. In my org we were discouraged to start new projects in Angular.
> It would be a truly herculean task to bring another framework up to the same level of support and integration of Angular inside Google.
And in fact, Cloud already did this.
Unfortunately, what they chose to bring up to the same level was... Angular, when they transitioned off AngularJS.
They moved from a framework with known performance pitfalls to a framework with slightly fewer known performance pitfalls. It was the right move for them, but it only solved a handful of the problems they were having with the previous iteration of Angular.
It was infinitely ahead of its time when it was new... and then it was abandoned until it was miles behind the competition.
It's the Google Way.
(But truly, the headcount on Google's internal web tooling compared with the size of the organization is laughable. I watched lots of devs burn out trying to improve internal tooling, then quit, because the organization doesn't value it.)
Yikes, didn't realize they had the indecency to drink their own kool-aid. Angular, really? No wonder! Come to think of it, it's maybe been around a year since I last saw one of those tell-tale "page finishes loading to a blank page for 20 seconds before finally rendering" Angular sites
DNSCrypt needs meaningful industry support otherwise it's sadly irrelevant. I think by now we can all agree "industry support" basically means the 3 browser vendors. DoH has at least Mozilla and Google on board, and presumably Microsoft are tailing along.
>Note that DoH (and DoT) shipped in iOS 14 and Big Sur, though aren't particularly easy to enable.
Specifically, you must install a properly configured .mobileprofile with HTTPS/TLS in the DNSSettings > DNSProtocol part of the payload (along with DNS server addresses of course). Merely pointing at a DoH/DoT supporting DNS server in the settings GUI won't do it, the OS doesn't do any probing and automatically use it just because it's available. For applications DNS Settings is covered under the Network Extension framework [0].
It's definitely nice Apple now has this built-in, and since they're onboard with Cloudflare/Fastly maybe this new twist will be pretty fast too. But obviously they're going to have to make this more automated for it to really make a widespread difference, ideally it'd simply see if the supplied DNS server (manual or DHCP) could run DoH/DoT and then just use it by default with no interaction required.
Also, macOS will not let you enable a DoH profile and Little Snitch (or probably any other tool using the Network Extension framework) at the same time. I don't know if this is a bug or intended behavior, but it's a disappointment.
Anyone have any idea why they chose to require 'configuration profiles' here?
There are several tools that can push configuration profiles to many macOS or iOS devices in one go [1]. It's also the kind of thing you don't want users in managed environments messing with if they don't know what they're doing.
Also, don't 'configuration profiles' require that your Mac have an associated AppleID?
I can't see why they'd be connected; being able to configure network settings isn't a "feature" related to having an Apple ID.
The user's IP address is masqueraded by the proxy, and neither the DNS mothership (Cloudflare) nor the ISP get to see both who the user is and what they requested. It's an extremely desirable property DoH currently lacks
Tor is not a run of the mill SOCKS proxy, not least in that it inserts arbitrarily high latency into the user data path. On the other hand, an actual run of the mill SOCKS proxy would have visibility of the user's queries and their identity, defeating the purpose of the design.
> an actual run of the mill SOCKS proxy would have visibility of the user's queries and their identity, defeating the purpose of the design.
Why would it have visibility of the queries? If I send a TLS connection (containing my DoH query) through that SOCKS proxy, then the SOCKS proxy is unable to decrypt that TLS connection without breaking certificate verification and thus can't read my DoH query.
Opened this post expecting to be hating on another power grab dressed up as protocol engineering, but this one seems to actively /reduce/ the centralization of user data collection in DoH. Props to Cloudflare, I'm impressed.
The proxy sees the client IP, but can't look at the encrypted DNS request.
The DNS server sees (deciphers) the DNS query, but not the client IP address.
It's a proxy, but with the sensible data encrypted with the server's public keys to hide it from the proxy. Cloudflare never knows who is sending the requests. How can they get access to the data?
While individual clients may not be easily identifiable, there's still a measure of identification that could be made, if you were to configure the public key DNS server to send a different (but persistent) public key to each IP address which asks for the DNS record. (Probably an ISP's caching nameserver.)
You can't tell how many people are going to be covered by that public key, but you could probably make educated guesses, or combine this with other metadata.
They run both, or buy data from the company that runs the other half?
I'm not sure I see the point,tbh. If you want to control dns, why not resolve yourself, with whatever cache you need? And if you trust a company to do that for you - assuming the two companies do log "their half" - you're just a data breach, data broker agreement or an acquisition away from a commercial entity having all the data (again)?
Do you want Google and your ISPs to see everything? Cloudflare and maybe Apple (not sure what infrastructure they’d have in this if any)? Another company like Cloudflare?
I don’t know the answer but I’m curious to hear everyone’s thoughts. Personally I’d like to prevent Google and my ISPs but Cloudflare could easily become Google in many ways.
I would like someone to correct me if I am wrong, but I think we can never have 100% privacy because the destination IPs cannot be encrypted or hidden, so as long as the destination IP can be observed, the server that you are connecting at can be obtained (I know a server can host many web pages, but this requires the port, which cannot be encrypted either).
So I don't know to what extent this protocol can be useful.
This is "fixed" in DoH the same way it's "fixed" for encrypted SNI: by having a small number of superproviders servicing millions of domains.
With current encrypted SNI proposal, your privacy (between you and the superprovider) is /improved/ by talking to a site behind a large aggregating provider. It sucks (since the superprovider still sees everything), but that's how it is.
I'm more worried about persistent, authenticated/ID-linked TCP connections (e.g. APNS) providing the client IP over time to an application service provider (e.g. Apple, Slack, Google, Microsoft, et c), that is, city-level geolocation track history via geoip, than I am the ISP or carrier snooping on what websites I connect to.
Every iPhone connects to APNS for push notifications and stays connected, and, last I looked at the protocol, the client certificate was linked to the device serial number. That's quite a geoip tracklog dataset, and AFAIK you can't turn it off.
It's to the point now that to keep my city-level location private from Apple, I'm not putting SIMs in any of my iPhones/iPads any longer, and carrying a battery powered VPN travel router (with a SIM uplink in it) for them to talk to. Super annoying that it has to come to this.
> but I think we can never have 100% privacy because the destination IPs cannot be encrypted or hidden
This problem is solved in I2P (https://geti2p.net) by adding a few intermediate hops between you and destination. You will know someone is connecting to the network, but you can't find what they're doing.
yes you CAN if you wish of course. on the other hand nowadays 95% of domains on the Internet can be identified by IP[1][2]. so ISPs still have a pretty good guess what sites do you visit even without DNS or SNI data.
I think there's still pretty good worth in this protocol. DNS is one of the key areas where we voluntarily give away information on every single website we're connecting to to a third party. This protocol certainly helps that--as long as the proxy and recursive resolver do not collude, neither will be able to associate the websites you're looking up with your IP.
It does have its limitations; a MITM can still just as easily see which IP addresses you connect to and determine which websites are associated with those IPs. But ODoH isn't really meant to fix that. A VPN would be better suited to fix that particular privacy concern.
"""A key component of ODoH working properly is ensuring that the proxy and the DNS resolver never “collude,” in that the two are never controlled by the same entity, otherwise the “separation of knowledge is broken"""
Essentially this is no better than using an HTTP proxy or a VPN.
I still have doubts, 1.1.1.1 was a clear power grab and effort to control more of the internet. DoH in partnership with Mozilla was an extension of that
So I am still suspect of their motives but maybe the negative PR got to be too much
thanks for your feedback! we will try to clarify things on our next posts!
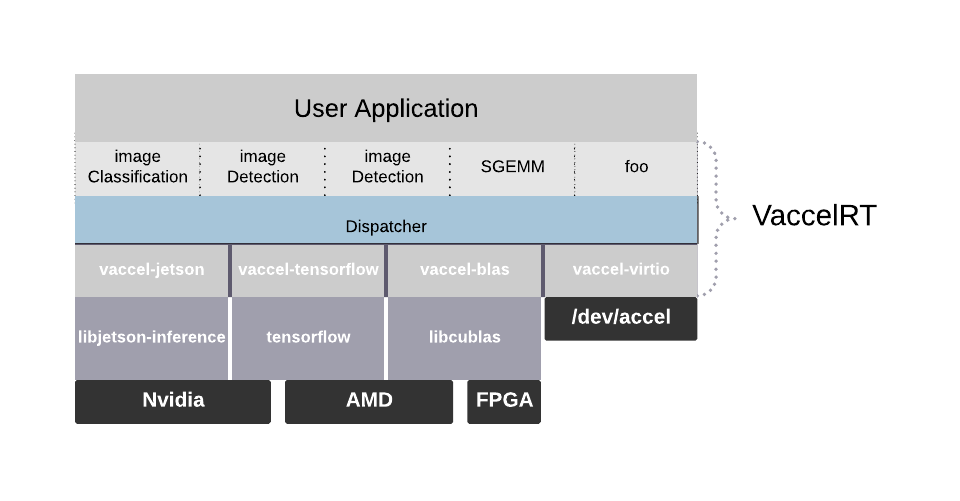
in short vAccel is a framework that translates function calls from users (upper side of this diagram) to the relevant functions of the respective acceleration framework (lower side of the diagram). For instance, calling a function like image_classify (user function) would result in the respective image_classify of jetson-inference, which would, in turn, execute the image classification function on the GPU and return the result to the user.
I tried LocalCDN after seeing a recommendation for it here, but despite claiming to cache more libraries it was very clearly not catching as many requests as DecentralEyes, which I'm back using now
This was always a land-grab by folk who wanted Docker's """community""" (read: channel) but not Docker's commercial interests. Any time you see a much larger commercial entity insist you write a spec for your technology, especially one with much larger pockets, the writing is always on the cards.
The bit that absolutely fucking sickens me is how these transactions are often dressed up in language with free software intonations like "community", "collaboration" etc. Institutionalized doublethink is so thick in the modern free software world that few people even recognize the difference any more. As an aside, can anyone remember not so long ago when Google wouldn't shut up about "the open web"? Probably stopped saying that not long after Chrome ate the entire ecosystem and began dictating terms.
The one mea culpa for Docker is that the sales folk behind Kubernetes haven't the slightest understanding of the usability story that made Docker such a raging success to begin with. The sheer size of the organizations they represent may not even allow them to recreate that experience if indeed they recognized the genius of it. It remains to be seen whether they'll manage that before another orchestrator comes along and changes the wind once again. The trophy could still be stolen, there's definitely room for it.
The whole idea of containerization came from Google anyways, who uses it internally. Docker came out with their container system without understanding what made it work so well for Google. They then discovered the hard way that the whole point of containers is to not matter, which makes it hard to build a business on them.
Docker responded by building up a whole ecosystem and doing everything that they could to make Docker matter. Which makes them a PITA to use. (One which you might not notice if you internalize their way of doing things and memorize their commands.)
One of my favorite quotes about Docker was from a Linux kernel developer. It went, "On the rare occasions when they manage to ask the right question, they don't understand the answer."
I've seen Docker be a disaster over and over again. The fact that they have a good sales pitch only makes it worse because more people get stuck with a bad technology.
Eliminating Docker from the equation seems to me to be an unmitigated Good Thing.
> The whole idea of containerization came from Google anyways, who uses it internally.
Not really. Jails and chroots are a form of containerization and have existed for a long time. Sun debuted containers (with Zones branding) as we think of them today long before Google took interest, and still years before Docker came to the forefront.
> I've seen Docker be a disaster over and over again. The fact that they have a good sales pitch only makes it worse because more people get stuck with a bad technology.
> Eliminating Docker from the equation seems to me to be an unmitigated Good Thing.
Now this I agree with, Docker is a wreck. Poor design, bad tooling, and often downright hostile to the needs of their users. Docker is the Myspace of infra tooling and the sooner they croak, the better.
What Google pioneered was the idea of defining how to build a bunch of containers, building them, deploying them together to a cloud, and then having them talk to each other according to preset rules.
Yes, we had chroot, jails, and VMs long before. I'd point to IBM's 360 model 67 which was released in 1967 as the earliest example that I'm aware of. A typical use before containerazation was shared hosting. But people thought of and managed those as servers. Maybe servers with some scripting, but still servers.
I'm not aware of anyone prior to Google treating them as disposable units that were built and deployed at scale according to automated rules. There is a significant mind shift from "let's give you a pretend server" to, "let's stand up a service in an automated way by deploying it with its dependency as a pretend server that you network together as needed". And another one still to, "And let's create a network operating system to manage all services across all of our data centers." And another one still to standardize on a practices that let any data center can go down at any time with no service disruption, and any 2 can go down with no bigger problems than increased latency.
Google standardized all of that years before I heard "containerization" whispered by anyone outside of Google.
Containers came from Solaris and the BSDs, and the warehouse-sized containerized deploys that this article/changelog is associated with came from Google. You're both right.
And agreed, Docker is a mess. It seems like everything that's good about Docker was developed by other companies, and everything that's bad about Docker was developed by Docker. The sooner the other companies can write Docker out of the picture the better. I want the time I wasted on Swarm back.
I get preferring that major open sourced projects weren't controlled by a big corporation, but this seems overly dramatic.
Docker was always a company first and foremost, I fail to see how leaving the technology in their commercial control would have been better in any way than making it an open standard.
Just because Docker = small = good and Google = giant corporation = evil? Docker raised huge amounts of VC funding, they had every intention of becoming a giant corporation themselves.
And it's kind of bizarre to completely discount the outcome of this situation, which is that we have amazing container tools that are free and open and standardized, just because you don't like some of the parties involved in getting to this point.
I would hesitate to use the term "open standard" until I'd thoroughly assessed the identities of everyone contributing to that open spec, along with those of their employers, and what history the spec has of accepting genuinely "community" contributions (in the 1990s sense of that word)
I've never tried contributing to CRI so I don't really know what the process is like. I imagine like any such large and established standard it would require a herculean effort, that doesn't necessarily mean it's not open just that it can't possibly accept any random idea that comes along and still continue to serve its huge user base.
But let's say you're right and call it a closed standard. Then this change drops support for one older, clunkier closed standard in favor of the current closed standard. Still doesn't seem like anything to get upset over.
The standardization of “Docker” containers into “OCI” containers and the huge amount of public pressure put on Docker to separate out their runtime containerd from dockerd.
Do you think it shouldn't have been standardized so other vendors products could be interoperable with docker's containers, or just that the standardization should have been done differently, or other?
{kind=link}
The technology of a vendor is way less important than its culture. So far Gcloud seems to understand that. Maybe the App Engine team is outside that org