>The precision of outages (at :29 and :44) matches a network-synchronized clock (NTP).
I think this just correctly points out that if the trigger was something unsynchronized like animals chewing on wires or someone digging underground, you wouldn't have 61% of events occurring at these two second markers. Even if the trigger was something digital but on a machine that isn't NTP synchronized, you would eventually have enough clock drift to move the events to other seconds. 61% combined at two markers (exactly 15 seconds apart) strongly suggests synchronized time.
Like many others have pointed out, Apple is obsessed with avoiding antitrust scrutiny. A fun (edit: incorrect) example: they are fine owning the device you use to connect to their own streaming service to watch their own produced TV shows, but appear to strictly avoid showing their products in those shows.
EDIT: I stand corrected! Multiple "Apple Original Series" contain Apple products, such as in Ted Lasso and (I think implied) in For All Mankind, as people pointed out below. Shows what I know about TV.
I wonder why some Apple Original Series have Apple products, and some don't. I would love to see if there's any correlation between the number of shows which feature a specific product and that product's market share in the show's region or demographic.
> but appear to strictly avoid showing their products in those shows.
Apple has 'villains can't use iPhones' rule. Directors are not allowed to use Apple product placement for villains.
Apple pushes their products in Apple TV+ and pays for product placements, or provides their products for free for other productions as as long as you follow the rules.
That is not true, just from first principles. You think anyone would watch Apple TV+ shows if there were no suspense or mystery because all the good guys use Apple stuff and all the bad guys use non Apple stuff?
Looking at the relevant limit, "Consecutive Authorization Failures per Hostname per Account"[0], it looks like there's no way to hit that specific limit if you only run once per day.
Ah, to think how many cronjobs are out there running certbot on * * * * *!
Nowhere in the blog post does it say they can't cope with the load, which is why the rate limits are so high. This is only about reducing wasted resources by blocking requests which are never going to succeed.
They definitely can't cope with the load at midnight, or at least couldn't back in 2022, and the fact that they mention midnight specifically in this post makes me assume they still can't. I say this because I had cert issuance fail for multiple days because of DB timeouts on their end from that: https://community.letsencrypt.org/t/post-to-new-order-url-fa...
Incidentally the fact that it took them 4 days to respond to that issue is why I'll be wary of getting 6-day certs for them. The only reason it wasn't a problem there was that it was a 30d cert and had plenty of time remaining, so I was in no rush. (Also ideally they'd have a better support channel than an open forum where an idiot "Community Leader" who doesn't know what he's talking about wastes your time, as happened in that thread.)
No, they will never get that short due to reliability issues. I could see getting down to maybe two weeks.
To make 24 hour valid certs practical you would need to generate them ahead of time and locally switch them out. This would be a lot more reliable if systems supported two certs with 50% overlapping validity periods at the same time.
Timezones going to make that hilarious, probably go back to much longer certs. I like free so I put up with LE. The automated stuff only works on half my servers, the other half I either run without https or I manually install it. Except now I wait until the service stops working, spend 15 minutes debugging why, go to the domain in a browser and see the warning, and then go fix it. Why? LE decided sending 4 emails a year is too many. And let's be real, sending automated emails is expensive. I think AWS charges like $0.50 per email when you use their hosted email sender.
By my memory, a cron runs a script that checks my cert file's last modified daily. When it is a certain number of days since (flavored Bash statements) the file last modified I'll certbot and install whatever comes back.
It's very under-engineered, maybe a trifold pamphlet on light A11 printed with a laser jet running out of ink.
I've probably spent more time talking about how much it sucks than I have bothered considering a proper solution, at this point.
>I've probably spent more time talking about how much it sucks than I have bothered considering a proper solution, at this point.
I respect this. Reading someone else write this makes me feel more comfortable thinking about the things in my life I could be doing more to improve, which makes me respect this even more.
Yep, the embedded video in the article really says it all. Proven Industries' wording here at at the very least ambiguous as to whether or not a shim that works on one lock will work on another of the same model.
If you had to take apart the lock to make a shim for only that lock, of course that would be misleading to suggest otherwise. Instead, they're going directly after the researcher for demonstrating the insecurity of an entire line of locks.
Either the TSA should sue the man who published photos of the "Travel Sentry" keys, or Proven Industries should look into rebranding as "peace of mind" locks :)
I assume autoexec is referring to the plethora of WebRTC vulnerabilities which have affected browsers, messengers, and any other software which implements WebRTC for client use. Its full implementation is seemingly difficult to get right.
Of course, you're right that this implementation is very small. It's very different than a typical client implementation, I don't share the same concerns. It's also only the WHIP portion of WebRTC, and anyone processing user input through ffmpeg is hopefully compiling a version enabling only the features they use, or at least "--disable-muxer=whip" and others at configure time. Or, you know, you could specify everything explicitly at runtime so ffmpeg won't load features based on variable user input.
>I assume autoexec is referring to the plethora of WebRTC vulnerabilities which have affected browsers, messengers, and any other software which implements WebRTC for client use. Its full implementation is seemingly difficult to get right.
Like what? I did a quick search and most seem to be stuff like ip leaks and fingerprinting, which isn't relevant in ffmpeg.
Here's a (very) small sample gathered from a search for "webrtc" on cve.org and picking high-severity CVEs affecting browsers:
* CVE-2015-1260
* CVE-2022-4924
* CVE-2023-7010
* CVE-2023-7024
* CVE-2024-3170
* CVE-2024-4764
* CVE-2024-5493
* CVE-2024-10488
Of course, I agree that it's not relevant to ffmpeg. But seeing "WebRTC" triggers the same part of the brain that looks out for unescaped SQL statements. Good opportunity to point out the difference in this implementation.
So you searched “WebRTC”, and then took the extraordinary step of… not actually reading any of them while simultaneous using them as supposed points? Quick question since you seem to know a lot about these CVEs and have spent a fair amount of time understanding them: how many of those were browser implementation issue?
This is like searching CVE for “node” and then claiming Node is terrible because some node packages have vulnerabilities. Low effort and intended to fit evidence to an opinion instead of evaluating evidence. “Linux” has 17,000 results; using your critical lens, all Linux is insecure.
When writing this inflammatory post, you seem to have forgot the bigger picture of the thread you are flaming.
We're discussing whether it's right to take a second look from a security standpoint when a software implements WebRTC. In this case, it's nuanced, and the implementation in FFmpeg is very different than the more complete implementations you find in browsers. And when browsers have implemented WebRTC, many vulnerabilities have followed.
So the double-take is justified here, even if only in principle. No one is saying WebRTC is insecure, or FFmpeg, or node, or Linux..........
I did a cursory read of each CVE. Wherever you got the idea I did not, you must have forgot to include it in your post. Just now, I picked one from random. It reports "Multiple WebRTC threads could have claimed a newly connected audio input leading to use-after-free."
Does that exactly qualify as an "implementation bug"? I don't know, and I don't care, because how you taxonomize a CVE has nothing to do with whether it's a vulnerability that was introduced when implementing WebRTC. And it is.
I forgot nothing, but you seemed to forget whose comment you were attempting to bolster. I “flamed” the useless injection of CVEs that attempt to legitimize someone’s point about the insecurity of a protocol, when that tiny amount of CVEs for a technology the world uses quite heavily almost unanimously point to poor implementation-specific issues, none of which inform the security or risk of the protocol itself, adding useless data that doesn’t further a conversation on security.
“No one is saying webrtc is insecure”? That is literally what the comment was doing, which you attempted to legitimize by listing browser-specific CVEs.
Someone pointed to a car fire and said gasoline caused the fire, and you posted pictures of car fires. There is a reason a Fire Investigator (like a security researcher would) considers the difference between what started a fire and an accellerant. WebRTC was not the cause of these vulnerabilities like you are trying to imply and like the opinion you attempted to legitimize.
“I don’t care” — clearly, if you couldn’t take the time to understand the difference, I’m not surprised.
> stuff like ip leaks and fingerprinting, which isn't relevant in ffmpeg.
If ffmpeg implements WHEP in the future then I'd certainly be concerned about both of those things when viewing a stream. Probably less so for serving a stream up, particularly via a gateway (the current implementation IIUC).
From the article it's sure starting to seem like people across the internet are just starting to realize what happens when you don't have just 3-4 search engines responsible for crawling for data anymore. When data becomes truly democratized, its access increases dramatically, and we can either adjust or shelter ourselves while the world moves on without us.
Did Google never ever scrape individual commits from Gitea?
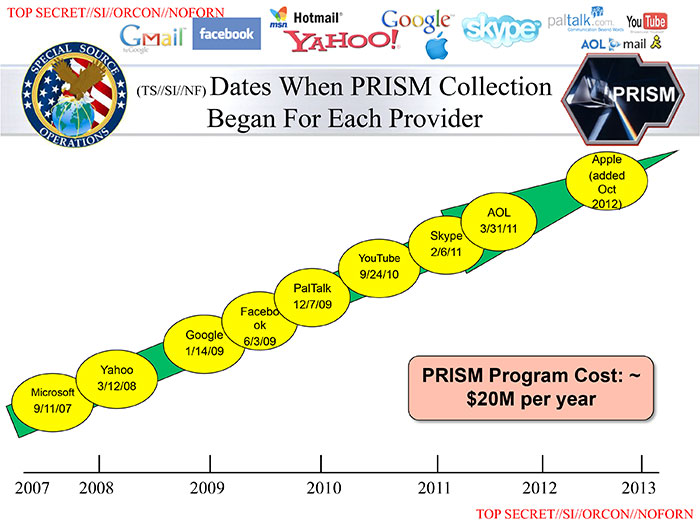
They only need to pay off or install a single employee to get total or near-total access. Consider this chart from 2013 showing when various tech companies were added to PRISM:
> lot of the companies embattled in the "constant litigation" mentioned by the GP are featured in this very chart
Yup. A great first step towards understanding these systems is to disaggregate the monoliths of these enterprises and the U.S. government into their power centres.
Do you believe the disaggregation of those monoliths helps to put the "hypothesis to bed"? It sure seems like you were listing "constant litigation" over "records request" as counterevidence of the claim that "if a company knows something about you, so does the government(s)".
If anyone in the U.S. government is extracting data from companies in a manner which is unlawful or should be (and they sure are), I see that as strong evidence of the hypothesis. Pointing out that local agencies may have to fight for their access in court doesn't change that it "is exactly the state of affairs the government prefers".
> sure seems like you were listing "constant litigation" over "records request" as counterevidence of the claim that "if a company knows something about you, so does the government(s)"
Yes. Just because the NSA can access some data doesn’t mean the entire federal government, including the NSA, has it.
> local agencies may have to fight for their access
The White House is fighting Harvard for student records. I don’t think people appreciate the degree to which information is siloed, intentionally and unintentionally, in the federal government. (It’s what led to DOGE likely committing multiple felonies.)
>I don’t think people appreciate the degree to which information is siloed, intentionally and unintentionally, in the federal government.
Thanks for that. Information can be completely siloed and the statements "If a company knows something about you, so does the government(s)" and "This is exactly the state of affairs the government prefers" still be correct.
Is your belief that the federal government has not actually purchased hordes of corporate surveillance data? Or is it that because there are examples of information being siloed or not available, that means it's okay or a non-issue that Americans' data that was once unlawfully collected is now still unlawfully collected but also collected by corporations and purchased wholesale by the federal government?
I... you're right. I was wondering why the world was only 9x9x9, there's 46k lines showing each block can have air, stone, grass, dirt, log, wood, leaves, or glass.
Incredible. I was so skeptical that I went in on the neckruff and from there to a lacetop, it's really all generated based on background-image but without using images but gradients of specific colors, as well as box-shadows and the like.
Similar problems on my MBP, actually – just sans crashed tab. Zooming in and scrolling around on Chrome and Safari cause the divs to rerender (repaint?) and often not all of them even do! E.g. Chrome: https://imgur.com/a/VWCAL9G
I don't think any on the first page are interactive. There might be a few on the next page of it (I only found one where a pen changes color on hover).
{kind=link}
>The precision of outages (at :29 and :44) matches a network-synchronized clock (NTP).
I think this just correctly points out that if the trigger was something unsynchronized like animals chewing on wires or someone digging underground, you wouldn't have 61% of events occurring at these two second markers. Even if the trigger was something digital but on a machine that isn't NTP synchronized, you would eventually have enough clock drift to move the events to other seconds. 61% combined at two markers (exactly 15 seconds apart) strongly suggests synchronized time.