Author here… I wrote it, I used Claude for proofreading/editing as mentioned at the end. Anyway point is, real human here!
I do still read the code _except_ when I am consciously vibe coding a non production thing where I will know empirically that it worked or not by using it.
I’m definitely not using agents to do all my coding (as I hope is reasonably) clear from the post. But they have crossed this line from pointless to try to genuinely useful for many real world problems in just the last couple of months in my experience.
Author of the piece here :-). We are not building coding agents and focused on quite different stuff… I am just trying to share my personal experience as a software person!
~~Counter~~ add to that - Armin Ronacher[0] (Flask, Sentry et al.), Charlie Marsh[1] (ruff, uv) and Jarred Sumner[2] (Bun) amongst others are tweeting extensively about their positive experiences with llm driven development.
My experience matches theirs - Claude Code is absolutely phenomenal, as is the Cursor tab completion model and the new memory feature.
Not a counter — antirez is posting positive things too.
Charlie Marsh seems to have much better luck writing Rust with Claude than I have. Claude has been great for TypeScript changes and build scripts but lousy when it comes to stuff like Rust borrowing
I'll add - they do seem to do better with Go and Typescript (particularly Next and React) and are somewhat good with Python (although you need a clean project structure with nothing magic in it).
This one seems really sloppy and confused; he describes three "modes of vibe coding" that involve looking at the code and therefore aren't vibe coding at all, as the definition he quoted immediately previously from Karpathy makes clear. Maybe he's writing his code by hand and letting Claude write his blog posts.
Not OP, and I don't have specific stake in any AI companies, but IMHO (as someone doing web-related things for a living (as a developer, team lead, "architect", product manager, consultant, and manager) since 1998, I think we pretty much all of us have skin in the game, whether or not we back a particular horse.
If you believe that agents will replace software developers like me in the near term, then you’d think I have a horse in this race.
But I don’t believe that.
My company pays for Cursor and so do I, and I’m using it with all the latest models. For my main job, writing code in a vast codebase with internal frameworks everywhere, it’s reasonably useless.
For much smaller codebases it’s much better, and it’s excellent for greenfield work.
But greenfield work isn’t where most of the money and time is spent.
There’s an assumption the tools will get much better. There are several ways they could be better (e.g. plugging into typecheckers to enable global reasoning about a codebase) but even then they’re not in replacement territory.
I listen to people like Yann LeCun and Demis Hassabis who believe further as-yet-unknown innovations are needed before we can escape a local maxima that we have with LLMs.
Author of the post here… Cool to see this back on HN! I was trying to provide instructions that anyone could use regardless of platform, hence the choice of web tools (both those linked process the data locally). If you know of a base32 decoder that’s easily available on Windows, Mac and Linux I’d be delighted to update the post.
OpenSSL, base32, basez, C program, Python or Lua script? I have a Lua script that generates TOTP (with base32 decoding), for example. What are your requirements, would either of these suffice?
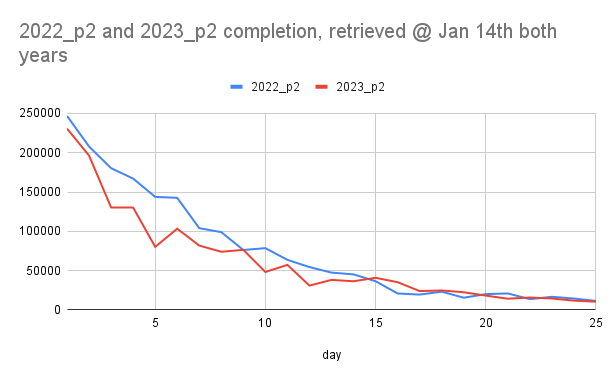
>This year’s Advent of Code has been brutal (compare the stats of 2023 with that of 2022, especially day 1 part 1 vs. day 1 part 2).
I enjoyed completing AoC this year. While it was very clear that day 1 (esp. part 2) was significantly harder than previous years (I wrote about this among other things [0]), OP's claim seemed not obviously self evident when comparing _current_ 2022 stats to _current_ 2023 stats, as folks have had an additional full year to complete the 2022 puzzles.
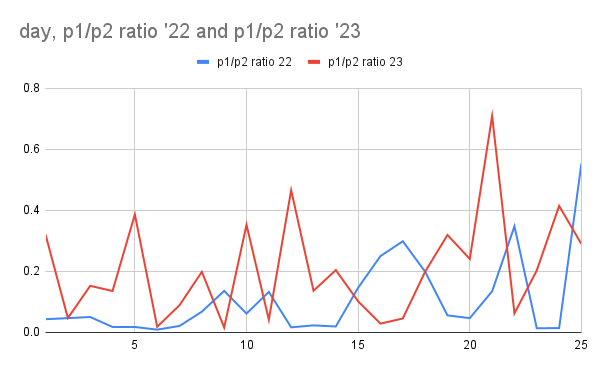
I grabbed the 2022 stats from Jan 14th 2023 [1] and, indeed, the difference is quite stark. Graphing the part two completion stats[2] for both years, there was a relatively similar starting cohort size on day 1, but 2023 looks clearly harder than 2022 up until day 15. As OP observes, the ratio[3] of folks completing pt1 but not going on to complete pt 2 is way higher for a lot of days in 2023 and suggests the day 5, 10, 12 and especially day 22 part 2s were particularly difficult.
Early AoC was fun, you could get away without anything fancy until late in the game. Then it got harder, not fun, so I gave up and stopped touching it.
I didn't get very far into AoC this year as I ran out of time. Maybe I'll pick it up again later.
But my point is, I was surprised at how hard day 5, part 2 was. I didn't give up and solved it, but went away wondering whey I'd missed something obvious and overcomplicated it. So it brings some relief to know it was 'supposed" to be a bit challenging!
This was just my personal experience (which certainly came from trying out a different language than I typically use in my day to day), but I'd argue that day 1 part 2 wasn't _hard_, but improperly specified from the prompt. The examples given are:
There is one critical example missing from this set and you can't exactly just figure out how you're meant to substitute the values without an example like:
Thanks for the details. To add to this discussion, I have a script to see the progression over the days.
Looking at the last two columns, you can see how brutal 2023 was compared to 2022. Especially in the beginning. The first few days, most people keep playing, with a retention higher than 80% most days, and virtually everyone people solve both parts. In contrast, only 76% of people solved part 2 after solving part 1. And many people gave up on days 3 and 5.
Interestingly, the last few days are not that much lower. And that can be explained by the fact that AoC 2023 is more recent than AoC 2022, like you said. My interpretation is that this group of people will get over all the challenges regardless of the difficulty (to an extent, of course), while many other people will give up when they realize it will take too much of their time.
I've been making wine at home in California for the past few years. Finding grapes on Craigslist/via friends, picking them myself and fermenting/storing/bottling wine in my basement. It's great fun, and tastes pretty good too! I wrote up a guide for anyone who'd like to try here - https://wine.singleton.io/
That's a reasonable question. We wrote this RCA to help our users understand what had happened and to help inform their own response efforts. Because a large absolute number of requests with stateful consequences (including e.g. moving money IRL) succeeded during the event, we wanted to avoid customers believing that retrying all requests would be necessarily safe. For example, users (if they don’t use idempotency keys in our API) who simply decided to re-charge all orders in their database during the event might inadvertently double charge some of their customers. We hear you on the transparency point, though, and will likely describe events of similar magnitude as an "outage" in the future - thank you for the feedback.
{kind=link}
{kind=link}
Fun to see this post from the deep archive get some interest - thanks for reading!